

Автоматическое выявление аномалий в сетевом трафике с помощью ИИ и интеграция в SOC
Изображение: recraft
Современные SOC (Security Operations Center) сталкиваются с огромными объемами сетевого трафика и разнообразием атак, при этом далеко не каждый SOC покрывает даже половину матрицы MITRE ATT&CK. Автоматизация с использованием ИИ существенно ускоряет обнаружение аномалий и минимизирует человеческий фактор.
В статье я расскажу о практических рекомендациях по развёртыванию решений автоматического выявления аномалий в российских реалиях, на базе отечественной экосистемы и с учётом регуляторных требований. Современные подходы к обеспечению кибербезопасности требуют широкого применения автоматизированных средств для обнаружения и реагирования на аномалии в сетевом трафике. Интеграция ИИ-решений в процессы Security Operations Center (SOC) становится необходимой для повышения эффективности мониторинга и ускорения реагирования на инциденты.
Рассмотрим международные и российские стандарты:
- ISO 27001/27002: Базовые стандарты для построения систем управления информационной безопасностью, включающие процессы мониторинга и реагирования.
- NIST Cybersecurity Framework: Рекомендует многоуровневую защиту, автоматизацию реагирования и использование современных систем корреляции событий.
- ФСБ и ФСТЭК Россия: Требования к СЗИ, в том числе по автоматизации обнаружения атак и инцидентов для критически важных объектов.
- Методики ГосСОПКА: Определяют классы систем мониторинга (NTA, IDS/IPS) и обязательное применение автоматизированных средств для анализа трафика и выявления аномалий.
Предлагаемая архитектура решения:
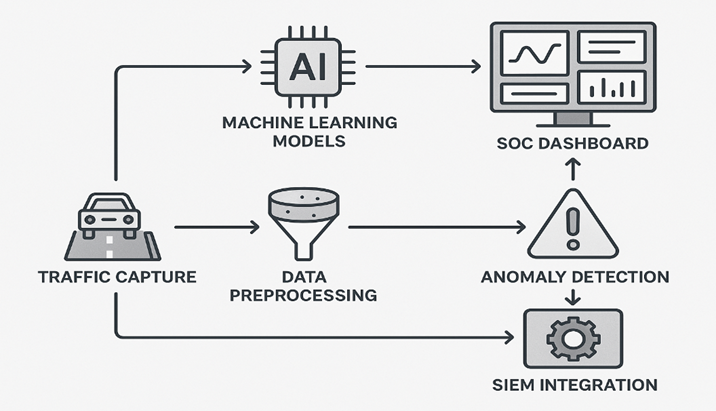
Шаг 1. Захват сетевого трафика
Источники данных:
- SPAN-порты коммутаторов, зеркалирование сетевого трафика.
- TAP-устройства, если необходима минимальная задержка.
- Интеграция с сетевыми шлюзами и фаерволами.
Рекомендация: Выделите отдельный сегмент для мониторинга, чтобы избежать перехвата лишнего трафика.
Шаг 2. ML-препроцессинг
- Экстракция признаков, агрегация статистики
- Выбор и внедрение российского AI-NDR/NTA решения:
| Решение | Ключевые возможности | Интеграция |
| PT NAD | Глубокий ML-анализ, собственная экспертиза | SIEM, SOAR, CMDB |
| Kaspersky KUMA | ML-модули + сценарии реагирования | Инцидент-менеджмент, почта |
| ViPNet IDS TIAS | Адаптация под российские ГОСТ и ФСТЭК | SOC, внутренние базы |
| Garda NDR | Аномалии сложного поведения, API коннекторы | SIEM, SOAR |
| Zeek | Глубокий NSM, скриптовое описание событий, детектирование аномалий | SIEM/SOAR через open format, SOC |
| Suricata | IDS/IPS, сигнатурный и поведенческий анализ | SIEM, распределённое размещение |
| RITA | Выявление beaconing, команд C2, машинное обучение | SIEM, отчётность csv, ELK |
| ElastiFlow | Веб-дэшборды, анализ NetFlow/sFlow/IPFIX, метода аномалий | ELK-stack, интеграция в SOC |
| ntopng (free) | Анализ трафика до L7, поведенческие сигнатуры | Дэшборды, экспорт потоков |
Шаг 3. Обучение и адаптация моделей
- Обучение под конкретную инфраструктуру, применение unsupervised и semi-supervised методов
- Используйте только свой трафик для обучения модели — это существенно снижает процент ложных срабатываний
- Проводите тестирование на “исторических” датасетах (например, записи NetFlow за последние 1-3 месяца)
- Регулярно обновляйте модель препроцессингом новых шаблонов поведения
Шаг 4. Интеграция в SOC-процесс
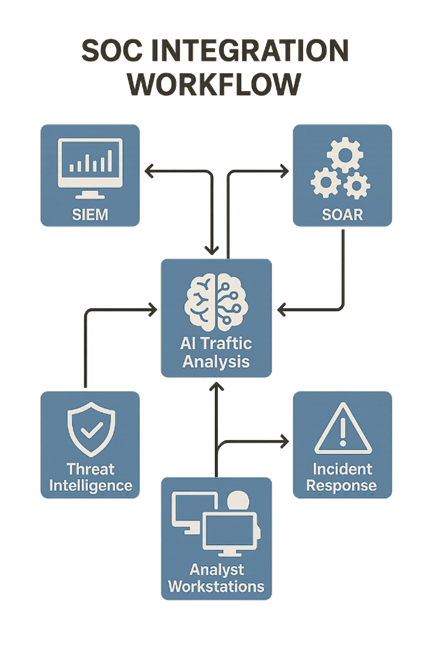
Технические шаги:
- Передача алертов, автоматическое создание инцидентов, связь с playbook’ами
- Свяжите AI-NDR/NTA платформу с SIEM (например, через syslog, API или готовый коннектор)
- Настройте алерты на создание инцидентов автоматически
- Внедрите автоматическую triage-обработку для сортировки событий по критичности
Организационные действия
- Обучите SOC-аналитиков работе с ML-алертами, отличию аномалий от “шумовых” событий, при возможности настроить фильтрацию в IRP/SOAR
- Уточняйте playbook’и реагирования: определяйте сценарии автоизоляции, нотификации, расследования
Шаг 5. Контроль эффективности
- Мониторьте MTTR (среднее время реагирования) и MTTD (среднее время детектирования)
- Ведите статистику по ложным срабатываниям: регулярный анализ причин, настройка новых признаков
- Настройте регулярную отчётность для руководства (динамика алертов, повторяемость паттернов аномалий)
Примеры реальных практик:
- Импортозамещение: После внедрения PT NAD и дообучения моделей на данных исключительно российской инфраструктуры, количество ложных срабатываний сокращается до 30–40% за несколько недель работы системы
- Скорость реагирования: Интеграция AI-модуля с SIEM позволяет обнаружить аномалию в корпоративной сети в течение минут вместо часов и сформировать задание на изоляцию или дополнительное сканирование сегмента
- Анализ инцидентов: Kaspersky KUMA в связке с автоматизированным инцидент-менеджментом обеспечивает быстрое расследование инициированных алертов и автоматическую передачу информации в ГосСОПКА
Рекомендации:
- Используйте тегирование потоков и метаинформации для гибкой фильтрации сетевых событий.
- Не ограничивайтесь только ML-модулями — комбинируйте их с экспертными правилами и «чёрными списками»
- Включите контроль шаблонов внутреннего трафика (lateral movement, сегментные аномалии)
ЗАКЛЮЧЕНИЕ
Автоматизация выявления аномалий на российском трафике, реализованная через отечественные решения, позволяет сократить время реакции, снизить ошибочные тревоги и формализовать взаимодействие SOC с регуляторами. Главный успех — постоянная адаптация моделей и тесная интеграция в рабочие сценарии вашей организации.
- Все указанные OpenSource-инструменты поддерживают экспорт данных в форматы, совместимые с российскими SIEM-системами и стеками SOC.
- Для повышения эффективности рекомендуется обучение моделей ML на локальных данных и регулярная настройка признаков аномалий под отраслевые сценарии.
- Используйте связку Zeek+Suricata для глубокого анализа и выявления сложных угроз.
- RITA особенно полезна для отслеживания скрытых каналов связи управления.
- ElastiFlow и ntopng подходят для визуализации больших потоков и удобной экспертизы инцидентов с минимальными затратами.
Внедряя NDR/NTA, вы снижаете TCO SOC, повышаете прозрачность алгоритмов и минимизируете риски “vendor lock-in”.
Практика показывает: максимальный эффект достигается не только от покупки решения, а в первую очередь — от настройки под свою инфраструктуру и регулярных ревизий паттернов угроз.

Автор: Беляев Дмитрий Александрович, Директор по Кибербезопасности в ИТ-компании, владелец телеграмм-канала BELYAEV_SECURITY
