




Черный ящик открытого кода: почему важно контролировать сторонние компоненты
Изображение: recraft
Почему открытый код стал главной мишенью злоумышленников и как выстроить защиту цепочки поставок
Разработка современного ПО немыслима без open source — сторонние компоненты позволяют опираться на опыт миллионов специалистов и в разы ускоряют создание продуктов. Только на GitHub за 2025 год число репозиториев с открытым исходным кодом выросло на 72 миллиона. В общей сложности на публичные репозитории сегодня приходится 63% всех хранилищ GitHub — это колоссальный объем открытого кода, на который полагаются компании по всему миру.

Однако рост популярности open source неизбежно влечет за собой новые риски. Специалисты «Кросс технолоджис», например, называют атаки через цепочку поставок ПО трендом 2025 года: по данным компании, на них пришлось 25–30% всех инцидентов (+90% год к году). Согласно отчету OWASP Top 10 за 2025 год, вид атак через цепочку поставок поднялся уже на третье место.
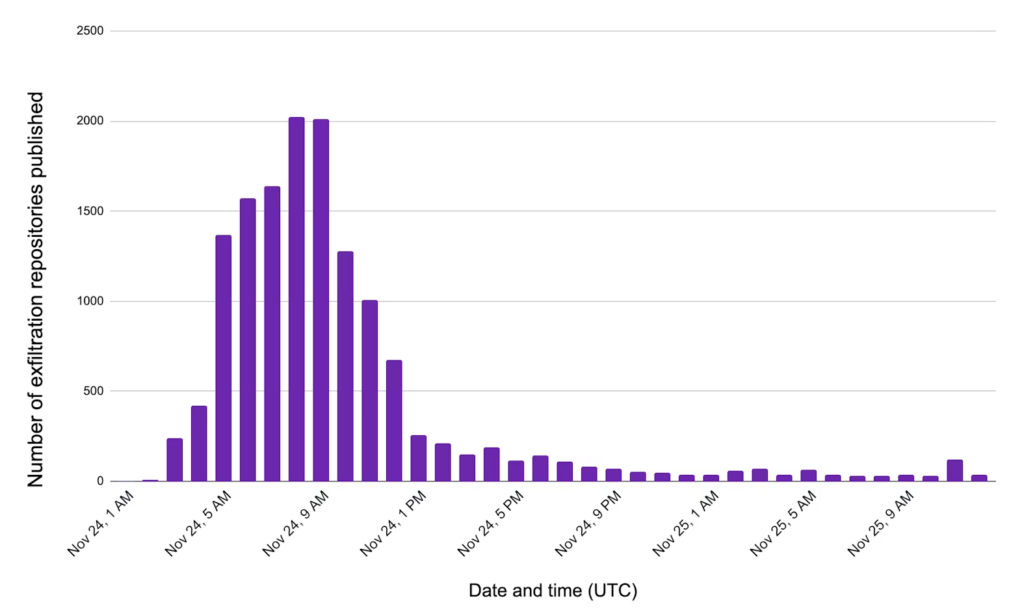
Яркий пример — червь Shai Hulud 2.0, который в ноябре атаковал NPM-пакеты с открытым исходным кодом. Вредоносное ПО извлекало секреты, доступные для конвейеров CI/CD, и загружало похищенные данные в публичный репозиторий GitHub, где к ним получали доступ злоумышленники.
Или другой кейс — в июле под удар попал популярный проект num2words для преобразования чисел в текст. Злоумышленники рассылали фишинговые письма разработчикам, которые использовали репозиторий PyPI, и в результате смогли загрузить две версии num2words со встроенным вредоносным кодом. Компании, установившие зараженное обновление, непреднамеренно запускали вредонос в свои системы.
Таких случаев десятки — проблема уже стала системной. Злоумышленники поняли:
Проще внедрить вредоносный код в одну популярную библиотеку, которую используют тысячи проектов, чем пытаться пробиться в каждый из них по отдельности. Парадоксально, но жизнеспособности таких сценариев способствуем и мы сами — потому что упорно «тащим» известные уязвимости в свои проекты.
По статистике CodeScoring, только за 2025 год было зарегистрировано 14 тысяч новых уязвимостей в открытых компонентах. По данным Sonatype, 95% загружаемых компонентов с уязвимостями уже имеют исправленные версии, но разработчики не всегда их используют и не обновляют пакеты. Яркий тому пример — Log4j. В 2025 году Log4j загружали из Maven Central почти 300 миллионов раз, и примерно 13% этих загрузок (около 40 миллионов) все еще содержали критическую уязвимость Log4Shell — несмотря на то, что безопасные версии доступны уже почти 4 года.
Чтобы защитить данные, необходимо действовать комплексно — в первую очередь развивать культуру безопасной разработки.
Безопасность как процесс: с чего начинать защиту
Реагировать на инциденты — это хорошо, но предотвращать их — еще лучше. Первый шаг к безопасному использованию open source — выстраивание грамотных процессов разработки внутри компании. К тому же открытые методики уже существуют и отлично работают.
Вот несколько примеров:
- OWASP SAMM (Software Assurance Maturity Model). Зрелый фреймворк от OWASP Foundation, который позволяет оценить текущий уровень защиты. Он помогает составить план совершенствования процессов безопасной разработки.
- Jet DAF (DevSecOps Assessment Framework). Открытая методология от Jet Security, которая также позволяет оценить зрелость процессов безопасной разработки и выбрать приоритетные направления развития. Преимущество — фреймворк адаптирован к международным стандартам, в том числе российским.
Также процессы безопасной разработки описывают нормативные документы. Актуальная версия стандарта для сертификации процессов, например, изложена в ГОСТ Р 56939-2024 «Защита информации. Разработка безопасного программного обеспечения. Общие требования». А в 2026 году ожидается публикация долгожданного ГОСТа по композиционному анализу ПО (КАПО), который учтет лучшие практики лидеров российского ИБ-рынка.
Инструменты безопасности
Важный этап развития процессов безопасной разработки — инвентаризация текущих проектов. Без понимания того, какие open source компоненты уже используются, любые разговоры об их безопасности бессмысленны. Нужно составить карту: что, где, каких версий и с какими лицензиями.
Ручная проверка всего объема ПО и отслеживание уязвимостей в сотнях библиотек — задача не просто трудоемкая, а порой невыполнимая. Здесь на помощь приходят инструменты композиционного анализа — SCA (Software Composition Analysis) или КАПО.
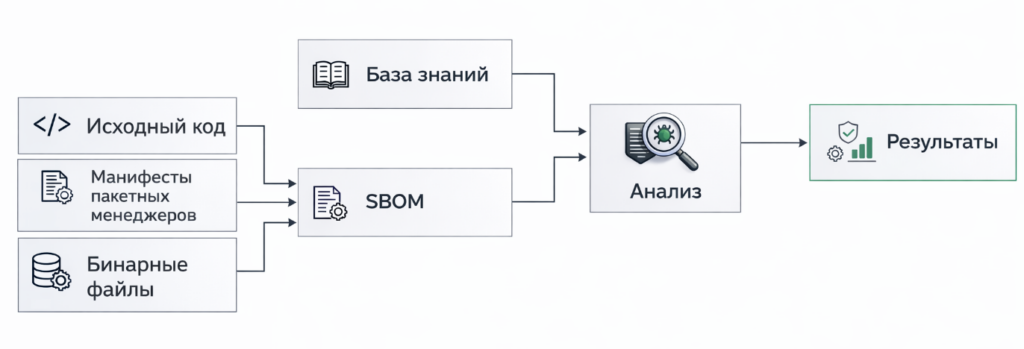
Схема работы инструмента SCA
Их задача — автоматически собирать информацию об используемых библиотеках, находить известные уязвимости и проверять лицензионную чистоту. На выходе мы получаем Перечень Программных Компонентов (ППК) — он же SBOM (Software Bill of Materials). Это детализированный документ, где по каждому компоненту указаны идентификатор, версия, ссылка на исходники, найденные уязвимости и рекомендации по исправлению.
ФСТЭК предъявляет строгие требования к таким перечням для сертифицируемого ПО. Так, например, согласно проекту приказа от конца 2025 года, ППК должны включать не только базовые атрибуты компонентов, но и дополнительные свойства вроде принадлежности к поверхности атаки или реализации функций безопасности. Инструменты вроде CodeScoring позволят автоматизировать формирование ППК в требуемом формате CycloneDX с учетом всех необходимых полей, что значительно ускорит подготовку материалов к сертификации и снизит риск замечаний от регулятора.
Казалось бы, достаточно установить анализатор, запустить сканирование — и можно жить спокойно. Но на практике в работе со SCA-инструментами есть три серьезных вызова.
Проблема первая: точность метаданных
Анализатор должен правильно определить, какие именно компоненты и версии используются в проекте. Для этого нужно учитывать нюансы работы каждой технологии, языка программирования и экосистемы пакетов. Если инструмент плохо «знает» специфику, например, Python или JavaScript, в ППК могут попасть неверные версии, а часть компонентов, наоборот — «потеряться».
Проблема вторая: полнота базы знаний
Допустим, анализатор нашел все компоненты. Но их еще предстоит сопоставить с информацией об уязвимостях. Для этого требуется база знаний — чем она полнее, тем лучше результат.
Сегодня разработчикам доступно много источников, которые отличаются наполнением и частотой обновления. Наиболее популярные:
- CVE. Централизованный каталог идентификаторов для известных уязвимостей безопасности в программном и аппаратном обеспечении от корпорации MITRE.
- Обобщенная база от GitHub. Источники разнообразны: помимо NVD, это собственные репозитории GitHub, прямые отчеты разработчиков, а также данные PyPA, RustSec и других экосистем.
- БДУ ФСТЭК России. Отечественная база уязвимостей, обязательная для многих регуляторных требований. Содержит уникальные записи, которых нет в западных источниках.
- Национальная база уязвимостей США (NVD). Крупнейший источник, содержит более подробные данные об уязвимостях, которым присвоен идентификатор в CVE. Однако далеко не идеален — информация часто приходит с задержкой, описания бывают обобщенными.
- Коммерческие фиды — например, от Лаборатории Касперского. Доступ нужно оплачивать, но они дают уникальные верифицированные данные и экспертную аналитику, которой нет в открытом доступе.
Проблема третья: масштаб результатов
Компании, которые успешно преодолели первые вызовы, в финале часто сталкиваются с еще одной проблемой — объемом данных. Чем больше проектов, тем масштабнее отчеты с перечислением уязвимостей, многие из которых — некритичные или дублирующиеся.
Если отдать эти отчеты разработчикам без предварительной обработки, они просто утонут в информации. Исправление проблем займет непозволительно много времени, а критичные риски затеряются в массе второстепенных.
Здесь на помощь приходит приоритизация. Методики вроде OWASP SAMM подсказывают, на что обращать внимание в первую очередь. А современные инструменты обладают дополнительными возможностями для упрощения работы с результатами.
Для более точной оценки, например, можно воспользоваться системой оценки CVSS, которая помогает понять критичность уязвимости, и EPSS, которая предсказывает вероятность эксплуатации уязвимости в ближайшие 30 дней. Кроме того, существует и классификация дефектов CWE. Она определяет тип уязвимости, помогает понять специфику атаки и выявить такие опасности, как внедрение вредоносного ПО (CWE-506).
В последнее время активно развивается направление проверки достижимости или применимости уязвимостей стороннего ПО. Это позволяет сузить круг первостепенных рисков за счёт проверки возможности эксплуатации уязвимости в рамках конкретного проекта или окружения.
Управление уязвимостями в open source: чек-лист
Безопасность open source компонентов — это обязательный элемент защиты любой современной компании. Атак через цепочку поставок становится больше, интерес злоумышленников к популярным библиотекам растет, и игнорировать этот вектор нельзя.
Что делать?
- Совершенствуйте процессы. Внедрите открытые методики (OWASP SAMM, Jet DAF), ориентируйтесь на нормативные документы (ГОСТ Р 56939-2024, будущий ГОСТ по КАПО).
- Проведите инвентаризацию того, что уже используете в разработке. SCA-анализаторы здесь помогут и автоматизируют поиск компонентов и уязвимостей. Но выбирать инструмент нужно с учетом технологического профиля компании — чтобы он понимал ваш стек, умел работать с нужными экосистемами и давал точные манифесты.
- Учитывайте ограничения. База знаний должна быть полной и актуальной, с экспертной верификацией и регулярным обновлением. Важно, чтобы она агрегировала данные из авторитетных источников — GitHub Advisory Database, БДУ ФСТЭК, NVD и коммерческих фидов.
- Учитесь приоритизировать. Результаты анализа должны фильтроваться с учетом CVSS, EPSS, CWE и применимости, чтобы разработчики не закапывались в отчетах, а сразу видели, что критично, а что подождет.
И главное, помните: защита open source — это не разовый проект, а непрерывный процесс. Технологии меняются, появляются новые уязвимости, эволюционируют методы атак. Выстроенная система позволит не просто реагировать на инциденты, а предотвращать их — и спать спокойно.
Автор: Антон Володченко, руководитель разработки продукта CodeScoring.

