

Что такое обезличивание, маскирование и токенизация, есть ли разница в этих терминах?
Изображение: recraft
Обезличивание, маскирование и токенизация — это методы защиты персональных данных и конфиденциальной информации, направленные на предотвращение несанкционированного доступа к данным.
Обезличивание — это общее понятие, которое предполагает удаление или скрытие информации, позволяющей идентифицировать конкретного человека, организацию или другой субъект, включая все виды чувствительных данных. Маскирование является частным случаем обезличивания и используется для скрытия отдельных элементов данных, таких как, например, паспортные номера, номера счетов или контактные данные, оставляя структуру данных пригодной для обработки. Алгоритмы маскирования позволяют обезличивать различные данные с сохранением формата и бизнес‑логики: например, корректно генерировать даты (с возможностью ограничения по диапазонам дней, месяцев и т. д.), маскировать номера банковских карт с сохранением платежной системы, банка-эмитента, типа карты, с пересчетом контрольного разряда, а также поддерживают другие структурированные типы данных.
Еще один из важных методов обезличивания информации — токенизация, метод защиты данных, при котором чувствительная информация заменяется безопасным токеном, а связь между ним и оригиналом хранится отдельно или нигде не хранится и построена на криптографии. Основная цель токенизации — предотвратить прямой доступ к оригинальным данным, снижая риск утечки, при этом обеспечивая возможность обработки и аналитики, а также восстановления исходных данных. Рассмотрим варианты токенизации:
Классическая (произвольная) токенизация:
- Токен создаётся случайным образом и не имеет математической связи с исходными данными;
- Преимущество: высокий уровень безопасности, невозможно восстановить данные без токен-базы;
- Недостаток: требуется централизованное хранилище токенов;
- Пример: 1234 5678 9012 3452 (номер карты) -> A1B2-C3D4-E5F6-7890 (токен);
Криптографическая токенизация:
- Токены формируются с помощью криптографических алгоритмов, включая FPE (Format-Preserving Encryption — шифрование с сохранением формата), AES CBC-CTS и других. При этом токены имеют математическую связь с исходными данными, поэтому не требуется хранить базу сопоставления токенов и исходных данных;
- Преимущество: сохраняют структуру данных, например, длину и формат номера карты, что удобно для систем, где требуется совместимость форматов. Для дополнительной защиты в FPE применяются понижающие словари, которые скрывают структуру исходных данных, а также предотвращают атаки на частоты и форматы. При этом токенизация позволяет проводить пре/пост обработку для пересчета контрольных разрядов, замены идущих подряд согласных/гласных и т.д. Еще одним из преимуществ токенизации — возможность восстановить исходное значение;
- Недостаток: имеется математическая связь с исходными данными;
- Пример: 1234 5678 9012 3452 (номер карты) -> 1234 5643 5612 4389 (токен); Иван -> Лова (токен);
Теперь поговорим об основных алгоритмах маскирования, которые присутствуют в системах обезличивания данных и в каких случаях они применяются.
- Посимвольная замена — метод маскирования, при котором каждый символ исходного значения преобразуется отдельно по заданному правилу, с возможностью сохранения определенных позиций или символов без изменений;
Применение: паспортные данные, номера документов и т.д.;
- Замена по словарю — замена по заранее сформированным словарям;
Применение: ФИО, адреса, организации, банки и т.д.;
- Перемешивание строк;
Применение: комментарии, зарплата, адреса и т. д.;
- Маскирование телефона с возможностью сохранения кода города, замены по справочнику и т. д.;
Применение: телефоны;
- Маскирование Email с возможностью разделения домена и имени для более точечной настройки маскирования;
Применение: электронная почта;
- Полная очистка (через NULL), в том числе бинарных файлов;
Применение: комментарии, бинарные файлы и т. д.;
- Замена на константу, в том числе бинарных файлов, уникальных значений и т.д.;
Применение: комментарии, бинарные файлы и т. д.;
- Маскирование даты с возможностью сохранения года, месяца, а также маскирования дат, связанных между собой;
Применение: даты рождения, даты выдачи и окончания документов;
- Маскирование с пересчетом контрольных разрядов;
Применение: ИНН, СНИЛС, ОГРН, ОМС, банковские карты и др.;
- Токенизация — замена значений на токены, в том числе с возможностью восстановления исходных данных;
Применение: любые данные;
- Минимальное-максимальное значение, для замен в диапазонах;
Применение: зарплаты;
- Замена по регулярному выражению — замена по специальному правилу на языке Regex;
Применение: любые данные;
- Нормализация — приводит различные слова к одному;
Применение: любые данные;
- Маскирование адреса, в том числе по базе ФИАС, ГАР, КЛАДР, замена координат в заданных диапазонах и т. д.;
Применение: адреса, координаты;
- Маскирование логов, в том числе с возможностью восстановления исходных данных;
Применение: журналы, файлы;
- Маскирование на основе признаков (пола, организации и т. д.);
Применение: ФИО, организации, банки, адреса и т. д.;
- Пользовательские алгоритмы — функционал, позволяющий создавать свои алгоритмы, например на языке Groovy, работать с составными колонками и т. д.;
Применение: любые сложные данные, где требуется дополнительная обработка текста и одновременная работа с несколькими колонками: хеширование, транслитерация, форматирование, объединение колонок и передача в другую и т. д.;
Все перечисленные методы обезличивания помогают организациям соблюдать требования законодательства не только о защите персональных данных, но и о сохранении конфиденциальной информации в целом — включая банковскую тайну, коммерческую тайну, служебную и иную охраняемую законом информацию. Такие подходы позволяют снизить риск раскрытия чувствительных сведений, обеспечить соблюдение регуляторных норм и повысить общую устойчивость инфраструктуры к утечкам и злоупотреблениям.
Какие типы маскирования бывают, что такое динамическое маскирование и как оно реализуется средствами СУБД?
Существует несколько подходов к маскированию данных. Их можно реализовать либо на уровне ETL-процессов (обычно через промежуточный сервер с отдельной копией базы), либо напрямую средствами SQL, когда обработка выполняется в самой СУБД и не требует дополнительных инфраструктурных ресурсов. Каждый метод решает свою задачу и подходит под разные сценарии безопасности:
- Статическое маскирование (SDM, In—Place) — выполняется внутри одной базы данных с использованием стандартных SQL-операций, через SELECT и UPDATE. Оригинальные данные заменяются на замаскированные, после чего их невозможно восстановить без резервной копии.
Преимущества подхода «In—Place»:
- Не требует сложной инфраструктуры;
- Используется меньшее количество дискового пространства;
- В некоторых случаях общий процесс обезличивания проходит быстрее чем в режиме «On-The-Fly» (*зависит от архитектуры БД);
Минусы подхода «In—Place»:
- Требуется разграничение прав доступа и дополнительный контроль, так как в определенной момент времени данные находятся в не обезличенном виде.
- Ошибки в маскировании удлиняют процесс, требуется восстановление данных из резервных копий;
- Маскирование «на лету» (On—The—Fly) — использует две базы данных: одну продуктивную (точнее ее копию) и одну «маскированную» копию (сначала формируется структура исходной БД, то есть ее слепок, далее в нее передаются уже замаскированные данные). Передача происходит с помощью операций SELECT и INSERT в целевую базу, при этом значения заменяются на лету. Такой метод чаще всего применяется для передачи данных из закрытого контура в открытый.
Преимущества подхода «On—The—Fly»:
- Позволяет проводить неограниченное количество (только в рамках ресурсов самой СУБД) повторных процессов маскирования, без необходимости восстановления из продуктивной базы (копии).
- Не требует дополнительного контроля доступа до и в момент маскирования, так как данные в исходную систему поставляются уже в замаскированном виде;
- Использование операций типа INSERT менее ресурсоёмко и работает быстрее, однако многое зависит от структуры БД.
Минусы подхода «On—The—Fly»:
- Требует отдельной базы и хранилища;
- Нужен механизм синхронизации данных между источником и маскированной копией. Он должен контролировать структуру источника и приемника;
- Динамическое маскирование (DDM) — технология, при которой маскирование применяется в момент выполнения запроса. Исходные данные при этом не изменяются. Пользователи с разными правами доступа видят разные представления одной и той же информации: одни — исходные значения, другие — частично скрытые или полностью замаскированные;
Реализация статического маскирования:
С помощью СУБД и скриптов: такие СУБД, как Oracle и Postgres, имеют дополнительный функционал статического маскирования, правда со своими ограничениями:
- Нет готовых алгоритмов, заточенных под российский рынок;
- Если в компании присутствуют различные типы СУБД, это делает задачу консистентности данных и поддержку такой системы практически невозможной или очень сложной;
- Зачастую требуют дополнительных дорогостоящих лицензий, например, как для СУБД Oracle;
- Требуют также держать отдельные команды разработки для разных типов СУБД;
- Требуют больших вычислительных ресурсов, так как алгоритмы маскирования и регулярные выражения для поиска часто выполняются непосредственно на самих СУБД;
С помощью специализированных систем по обезличиванию данных такой подход решает проблемы, описанные выше, а также значительно ускоряет и полностью автоматизирует процесс по предоставлению обезличенных тестовых сред, при этом позволяет соблюдать все нормативные требования РФ.
Реализация динамического маскирования:
- С помощью СУБД: многие современные СУБД (Microsoft SQL Server, Oracle, PostgreSQL) позволяют применять DDM средствами встроенных функций. Маскирование происходит на уровне SQL-запросов, используя правила для разных ролей пользователей;
- Через прокси и/или API: DDM можно реализовать между приложением и базой данных. Прокси перехватывает запросы и возвращает маскированные данные согласно политикам безопасности;
Преимущества подхода DDM:
- Отсутствие изменения оригинальной базы — исходные данные остаются целыми и не требуют восстановления из-за некорректных алгоритмов маскирования или ошибок в ходе обезличивания;
- Гибкая настройка прав доступа — разные пользователи видят только допустимую информацию;
- Ускорение внедрения — можно защитить данные без создания копий или сложной ETL-процедуры;
Теперь рассмотрим, какие встроенные механизмы маскирования данных предлагают популярные СУБД, какие ограничения и недостатки есть у этих подходов, а также разберём, как реализовано динамическое маскирование в Microsoft SQL Server, Oracle и PostgreSQL.
1. Microsoft SQL Server
SQL Server предоставляет встроенные возможности динамического маскирования данных (Dynamic Data Masking, DDM) для ограничения раскрытия конфиденциальной информации пользователям без соответствующих привилегий.
1.1 Динамическое маскирование данных (DDM, встроенное)
- Назначение: маскирует данные в Runtime без изменения самих данных, применяется к результатам запросов для непривилегированных пользователей;
- Версии: SQL Server 2016 (13.x+) и выше, Azure SQL;
- Стоимость: встроено, отдельная лицензия не требуется;
Алгоритмы маскирования:
- Default Masking: полная маскировка по типу данных;
Строки -> XXXX
Числа -> 0
Дата -> 1900-01-01
- Email Masking: раскрывает первую букву и домен;
Пример: aXXX@XXXX.com
- Random Masking: случайное числовое значение в указанном диапазоне;
Пример: 1–100
- Partial / Custom String Masking: раскрывает часть строки и маскирует остальное;
Пример: Roberto -> Rxxxxxo
- Datetime Masking (SQL Server 2022+): маскирует выбранные компоненты даты/времени;
Пример: только год, месяц или день
Ограничения и слабые места:
Нельзя маскировать:
- Вычисляемые столбцы;
- FILESTREAM;
- COLUMN_SET;
- Always Encrypted столбцы;
- Полнотекстовые индексы (FULLTEXT);
- Столбцы во внешних таблицах PolyBase;
Пользователь, у которого нет доступа к исходным данным может:
- Делать агрегаты: MIN(), MAX(), COUNT(), AVG();
- Использовать предикаты: WHERE, LIKE, IN, JOIN;
- Перечислять уникальные значения;
Это позволяет вычислять исходные данные через статистический анализ. Ниже я покажу пример SQL-скрипта, который позволяет перебирать замаскированные данные в СУБД MSSQL (через DDM).
Сначала добавим для колонки тестовую функцию маскирования, как показано ниже (важно отметить, что в отличие от Oracle и PostgreSQL, информация о замаскированных полях хранится в метаданных, доступ к которым по умолчанию есть у любого пользователя):
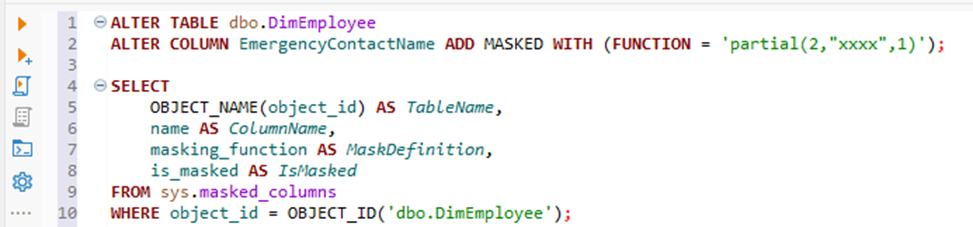
Пример того, как пользователи видят замаскированные данные:
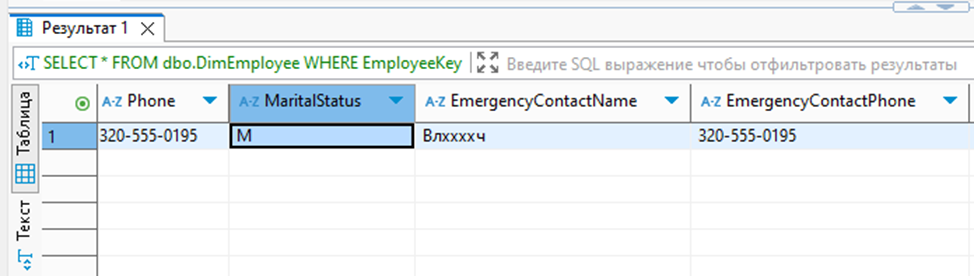
Пример того, как выглядят реальные данные:
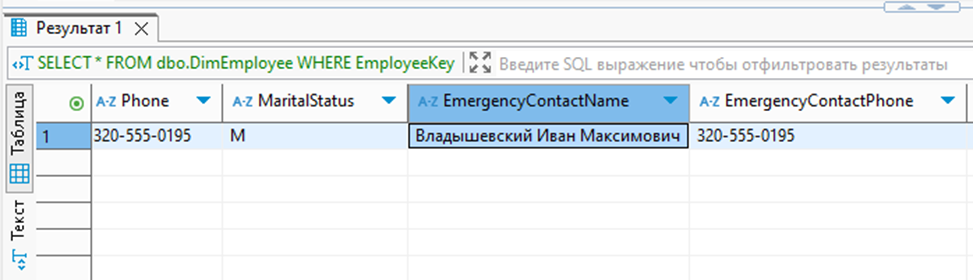
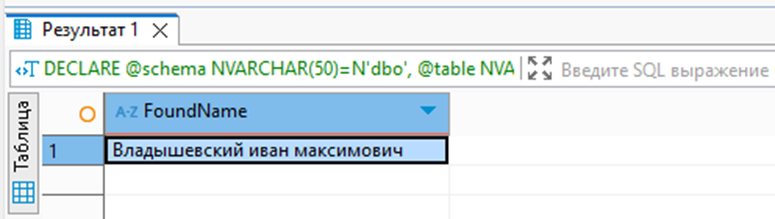
Теперь для демонстрации напишем небольшой скрипт, который будет перебирать значения замаскированных данных, пока не вернется пустой результат и мы не дойдем до конца словаря (с учетом даже если между словами есть пробел или даже несколько). Пример скрипта представлен ниже:

В результате работы скрипта получилось менее чем за 1 секунду подобрать замаскированное ФИО, как показано ниже (то же самое можно сделать для других колонок или целиком для всей таблицы):
2. Oracle
Oracle предоставляет полный набор средств для защиты и маскирования данных, как статического, так и динамического. Однако, стоит отметить, что помимо лицензии Enterprise, требуется дополнительная лицензия на маскирование (add-on) и/или Advanced Security Option.
1.1 Data Masking and Subsetting Pack (SDM, платное)
- Назначение: статическое маскирование данных и создание усеченных данных (subsets) для передачи в DEV/TEST, снижает риск утечек;
- Версии: Oracle 12c Release 1 (12.1+) и выше, через Oracle Enterprise Manager (редакция Enterprise);
- Стоимость: отдельный платный пакет OEM (не входит в Advanced Security Option), лицензируются только источники;
Алгоритмы маскирования:
- Substitution Masking: подмена значений по словарям (имена, города, email);
- Shuffle Masking: случайная перестановка данных в колонке (разрывает связи между ФИО и зарплатой);
- Blurring / Perturbation: «зашумляет» значения (± диапазон);
- Format Preserving Randomization: сохраняет длину и формат (Aa-9999 -> Bb-4217);
- Encryption (Reversible): форматосохраняющее шифрование (для последующего восстановления);
- Deterministic Masking: одинаковый вход -> одинаковый выход во всех базах;
- Conditional Masking: разные маски в зависимости от значения (US SSN -> XXX-XX-1234, UK NIN -> AB****CD);
- Compound Masking: согласованное маскирование связанных колонок (город + штат + ZIP);
- User-defined PL/SQL functions: любые пользовательские сценарии маскирования;
Возможности Subsetting:
Создание усеченных копий БД — например, выборка только за определённый период или по конкретному региону. Это сокращает размер тестовых баз и ускоряет Dev/Test процессы.
- Удаление ненужных строк перед передачей в DEV/TEST;
- Goal-based: например, 1% выборки из таблицы в 10 млрд строк;
- Condition-based: оставлять только клиентов после 2024 года / только один регион;
- Сохранение PK/FK целостности при вырезании данных;
Ограничения:
Нельзя маскировать:
- В связке с DISTINCT и ORDER BY
- В связке с GROUP BY
- Вычисляемые колонки
1.2 Data Redaction (DDM, платное)
- Назначение: маскирует данные в Runtime без изменения самих данных;
- Версии: Oracle 12c Release 1 (12.1+) и выше (редакция Enterprise);
- Стоимость: часть Advanced Security Option (платная, кроме Autonomous AI DB — для нее бесплатно);
Алгоритмы маскирования:
- Full Redaction: полная маскировка (числа -> 0, строки -> пробел);
- Partial Redaction: частичная маскировка (например, телефон +79161234567 -> +7916***4567);
- Regular Expression Redaction: маскирование по шаблону (email, паспорт, банковская карта, SSN и др.);
- Random Redaction: случайные значения при каждом запросе;
- Nullify Redaction: замена на NULL;
Совместимость:
- Oracle Database Vault: политики Redaction учитывают realm’ы; Пользователь без прав не видит данные и получает ошибки при DML/DDL;
- Real Application Security (RAS): защита колонок через права приложения (application privileges);
- Data Masking and Subsetting Pack: Redaction можно применять на non-production базах поверх уже замаскированных данных;
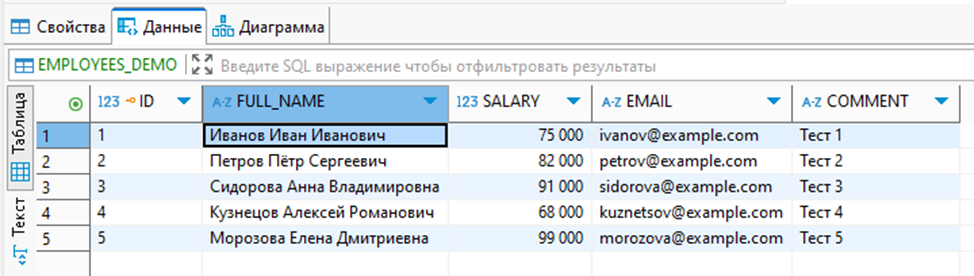
Результат работы динамического маскирования:
Пример того, как выглядят реальные данные:
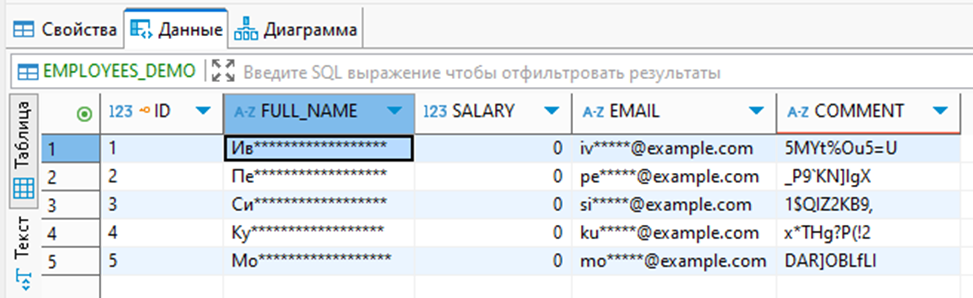
Пример как пользователи видят замаскированные данные:
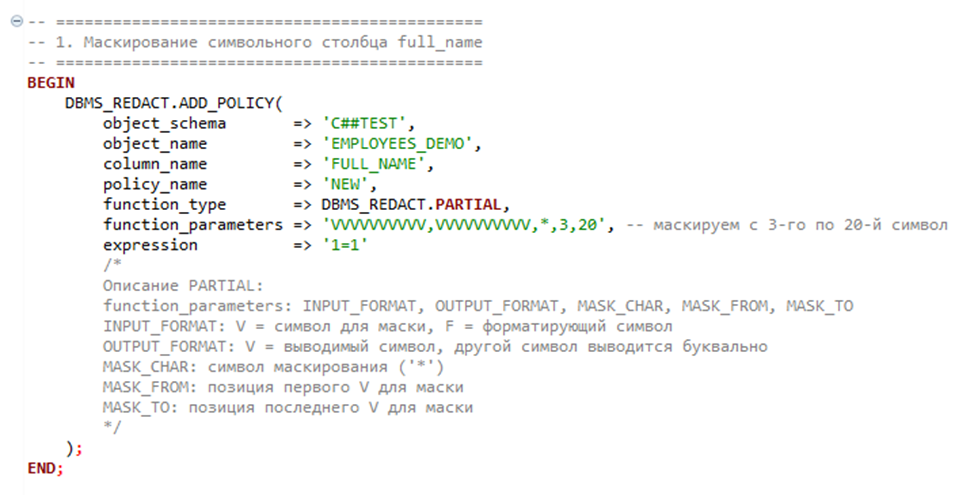
Примеры SQL запросов для настройки DDM:
Ниже представлены скрипты для включения динамического маскирования:
- PARTIAL
- REGEXP
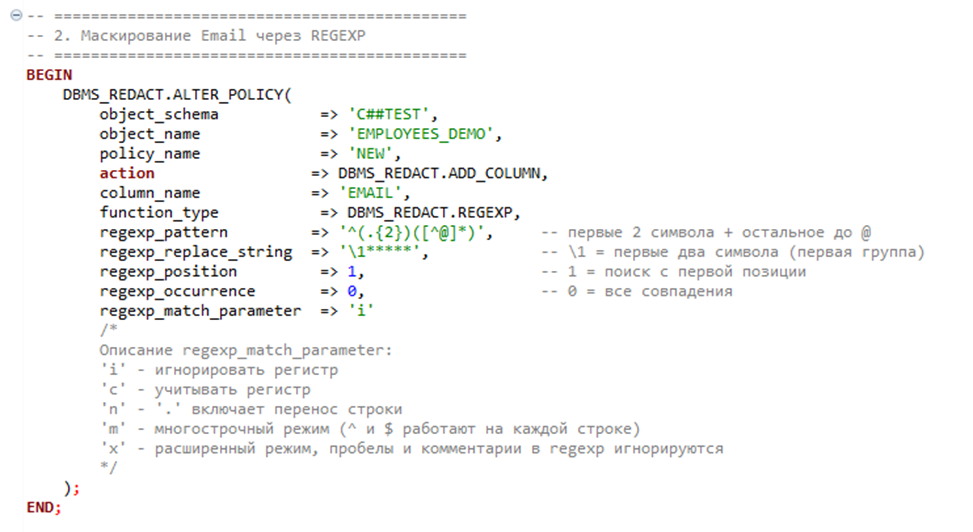
- RANDOM и FULL
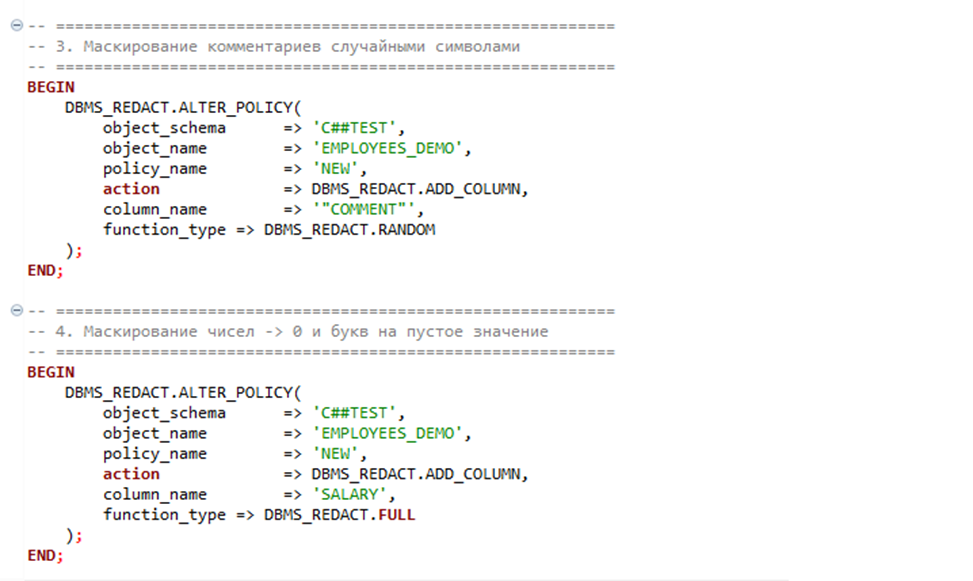
Минусы подхода:
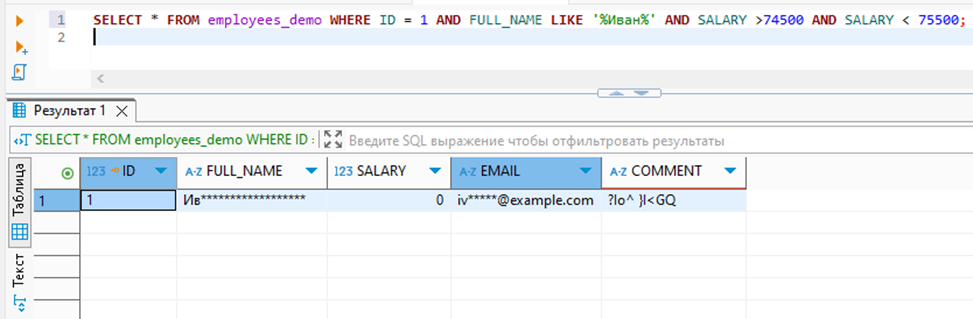
Пользователь, у которого нет доступа к исходным данным может:
- Делать агрегаты: MIN(), MAX(), COUNT(), AVG();
- Использовать предикаты: WHERE, LIKE, IN, JOIN;
- Перечислять уникальные значения;
Это позволяет вычислять исходные данные через статистический анализ, так же, как и в MSSQL. Пример такого запроса ниже:
3. PostgreSQL
PostgreSQL не имеет встроенного DDM/SDM в ядре, однако существует официальный плагин PostgreSQL Anonymizer («Anonymization & Data Masking for Postgres»), предоставляющий полноценное динамическое и статическое маскирование. Это расширение работает через декларативные политики, встроенные прямо в DDL.
Назначение: маскирование персональных или конфиденциальных данных с возможностью:
- Dynamic — скрывать данные в Runtime для непривилегированных пользователей, оригинальные данные остаются на диске.
- Static — физически изменять данные в таблицах (например, для передачи в DEV/TEST или архивирования).
Версии: PostgreSQL 11+
Стоимость: бесплатно, open source (pg_anonymizer)
Особенность: правила маскирования описываются в DDL таблицы и могут быть применены либо динамически при запросах, либо один раз для замены данных в таблице.
Методы применения маскирования:
- Anonymous Dumps
- Экспорт уже замаскированных данных в SQL-файл;
- Аналог статического экспорта «анонимной копии»;
- Static Masking
- Одноразовое применение правил к таблице (anon.anonymize_table()), реальные данные заменяются;
- Dynamic Masking
- Скрывает данные при запросах пользователей без привилегий;
- Оригинальные данные на диске остаются неизменными;
- Masking Views
- Создаёт виртуальные представления с масками для нужных ролей;
- Masking Data Wrappers
- Маскирует данные, полученное из внешних источников (через FDW);
Результат работы динамического маскирования:
В Oracle и MSSQL динамическое маскирование работает “на лету”, применяясь при выполнении SQL-запроса, но при этом фильтры WHERE и условия запроса все равно оперируют реальными значениями столбцов, поэтому исходные данные могут быть восстановлены. В PostgreSQL Anonymizer маскирование устроено иначе: движок SQL видит только уже подставленные маски, а не реальные значения, поэтому перебор условий или фильтров по исходным данным невозможен.
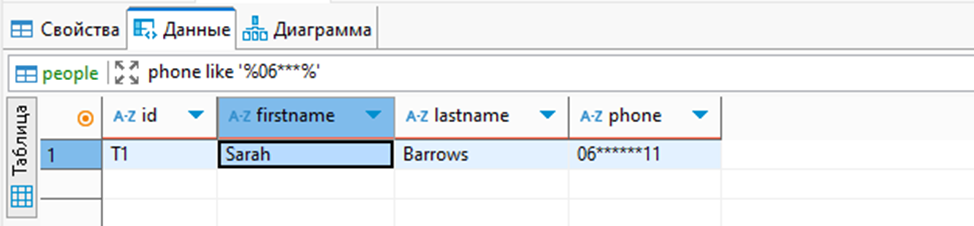
Пример того, как выглядят замаскированные данные (поле lastname при повторном запросе формируется заново):
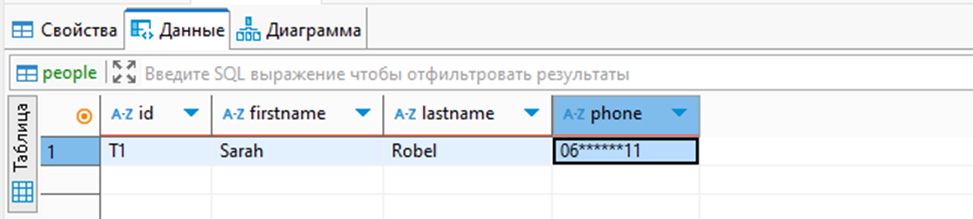
Если мы попробуем перебирать значения по маске, то мы будем работать не исходными значениями, а уже замаскированными, что не позволяет узнать исходные значения, как в Oracle и или MSSQL:
В заключение хочется отметить, что специализированные решения по обезличиванию данных значительно надежнее и практичнее, чем встроенные механизмы СУБД или самописные скрипты, поскольку они создаются под реальные процессы, требования регуляторов и особенности российского рынка. В отличие от встроенных и кастомных средств, такие платформы обеспечивают единообразие маскирования для разных типов СУБД, не требуют отдельных команд разработки и не зависят от дорогих лицензий производителей. Кроме того, такие решения не нагружают СУБД тяжёлыми операциями, обеспечивая стабильность, предсказуемость и значительно снижают риски утечек информации.
Как сейчас выбрать систему по обезличиванию данных, которая будет выполнять все нормативные требования и на что стоит обратить внимание?
Современное нормативное поле ужесточает требования к обработке конфиденциальной информации. Оборотные штрафы за нарушения достигают миллионов рублей, а репутационные риски становятся критическими для бизнеса. В этих условиях выбор системы обезличивания превращается из технической задачи в стратегическую.
На что стоит обратить внимание при выборе решения по обезличиванию данных:
Профилирование:
- Гибкость настройки, предустановленные алгоритмы поиска и валидации — в том числе поиск по бинарным файлам, а также использование Machine Learning;
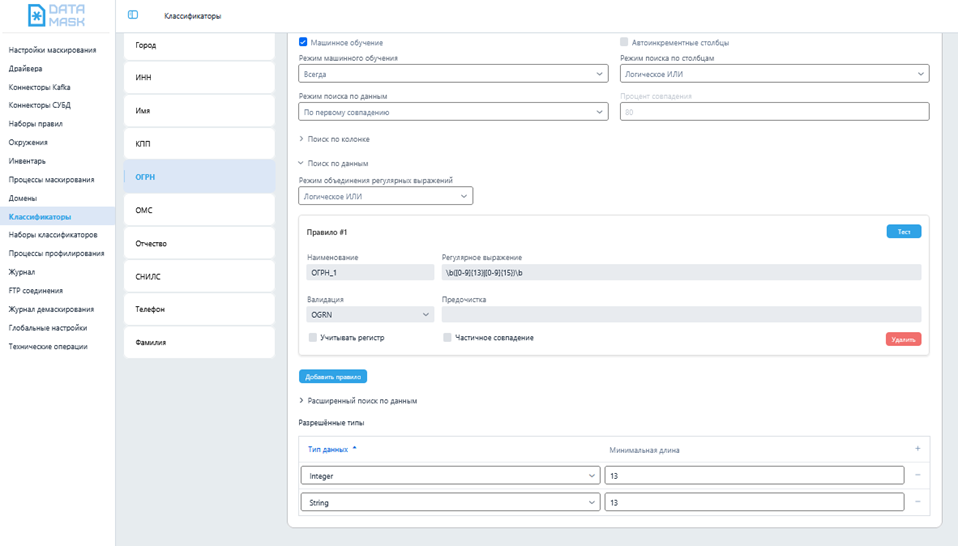
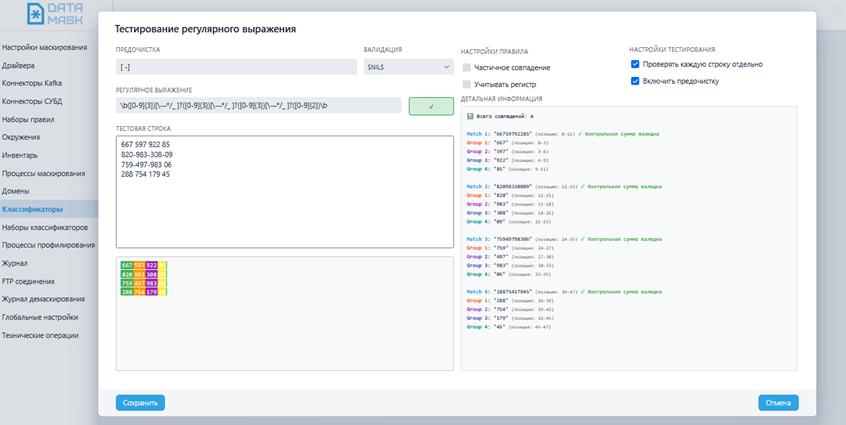
- Системы тестирования — для тестирования правил поиска без необходимости запуска на самом источнике;
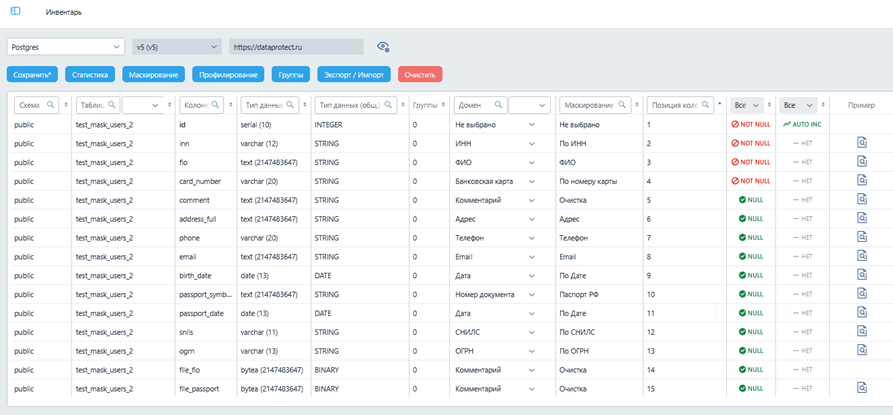
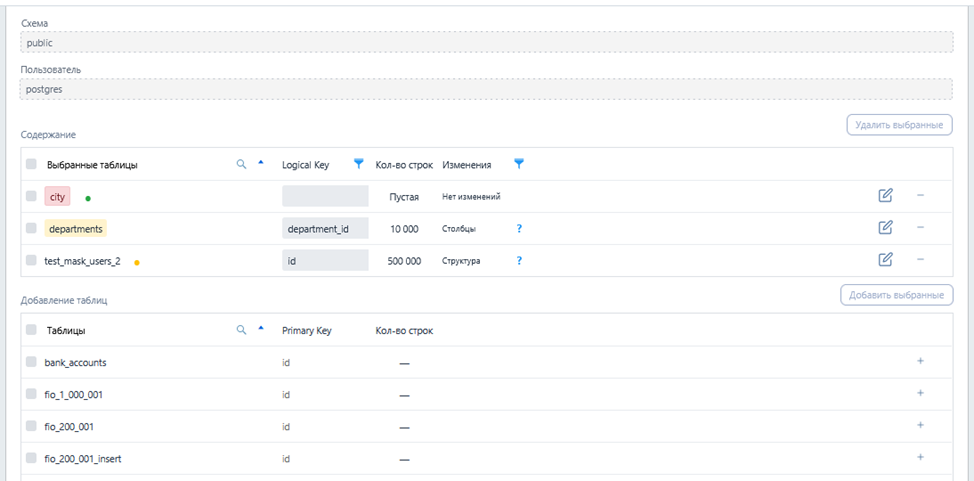
- Инвентарь для отображения структуры БД, ограничений и связей, с возможностью версионирования (для отслеживания изменений в БД и пользовательских настроек), настройкой алгоритмов, фильтрацией, выгрузкой в Excel, получения примеров (обезличенных, в том числе после применения алгоритмов маскирования, без необходимости подключения к БД);
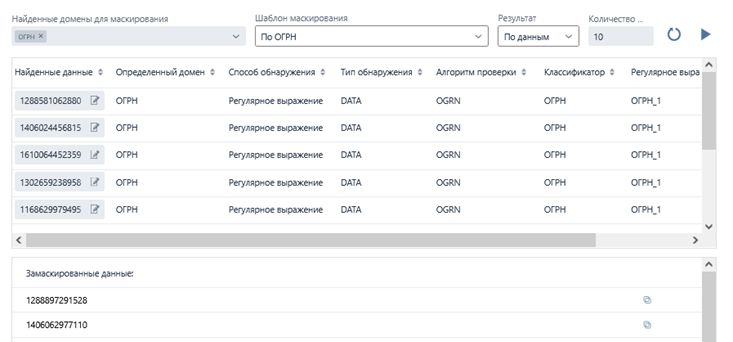
- Настройка наборов правил для гибкой фильтрации профилирования/маскирования и контроля пользовательских изменений, структуры БД и объемов исходных данных;
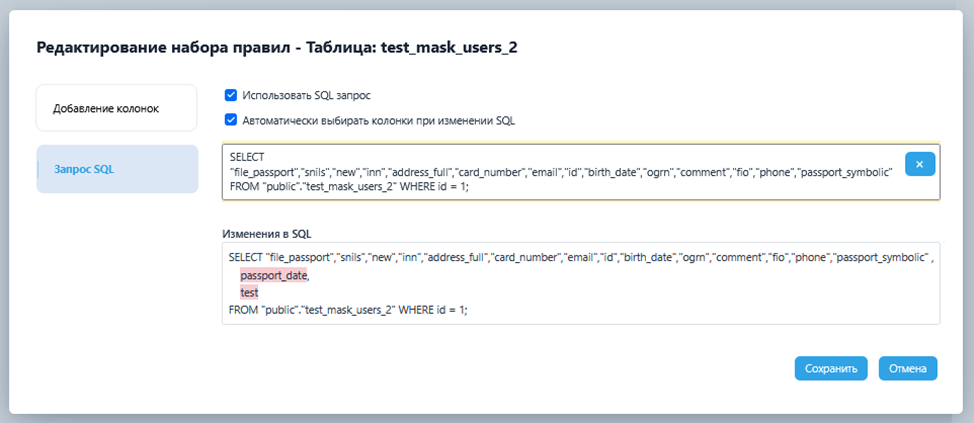
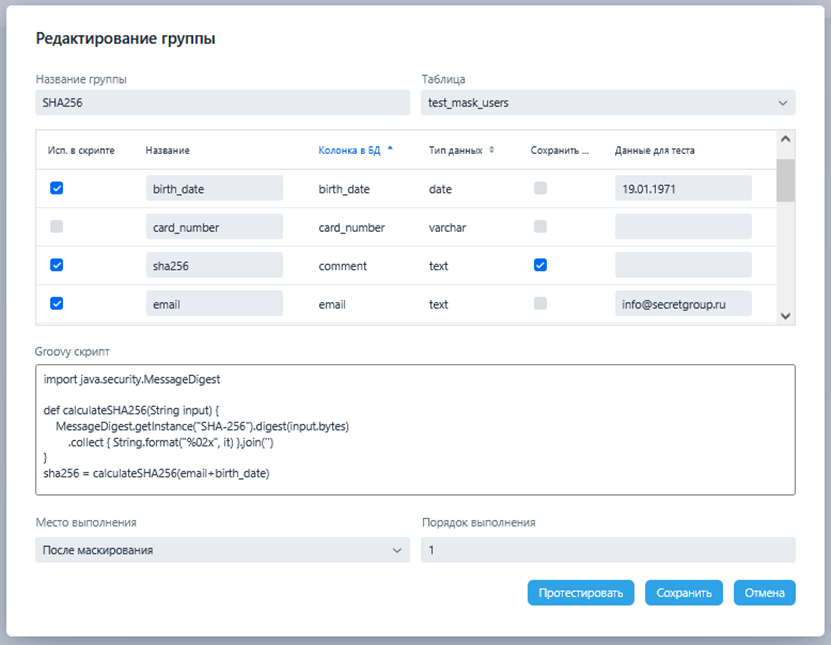
Маскирование:
Предустановленные алгоритмы маскирования, их перечень описал в начале статьи. В том числе с возможностью написания сложных пользовательских алгоритмов (например, для пересчета SHA256 после маскирования), а также работы с нескольким колонками одновременно (без необходимости создания отдельных процессов для последовательных операций);
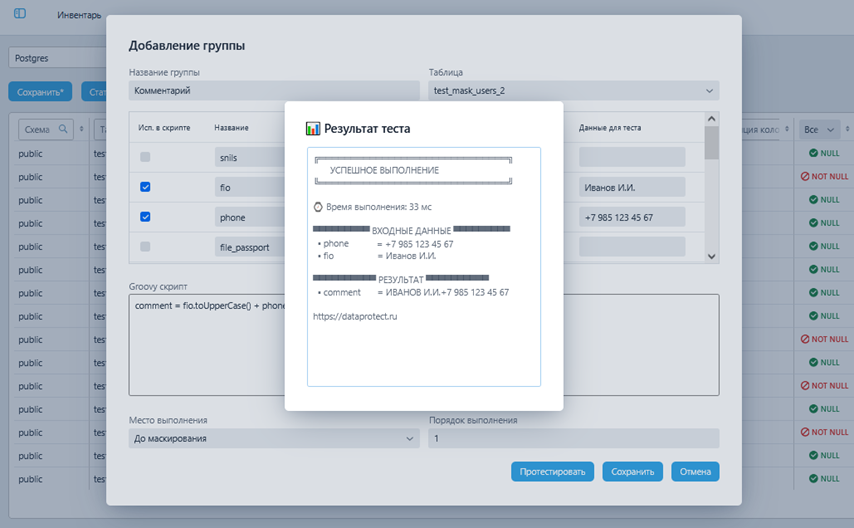
- Функционал SQL пред/пост обработки — для отключения/включения обвязки БД, а также выполнения пользовательских SQL скриптов, который генерирует SQL скрипты на основе структуры БД и выбранных алгоритмов маскирования, при этом давая возможность пользователю их редактировать, при необходимости;
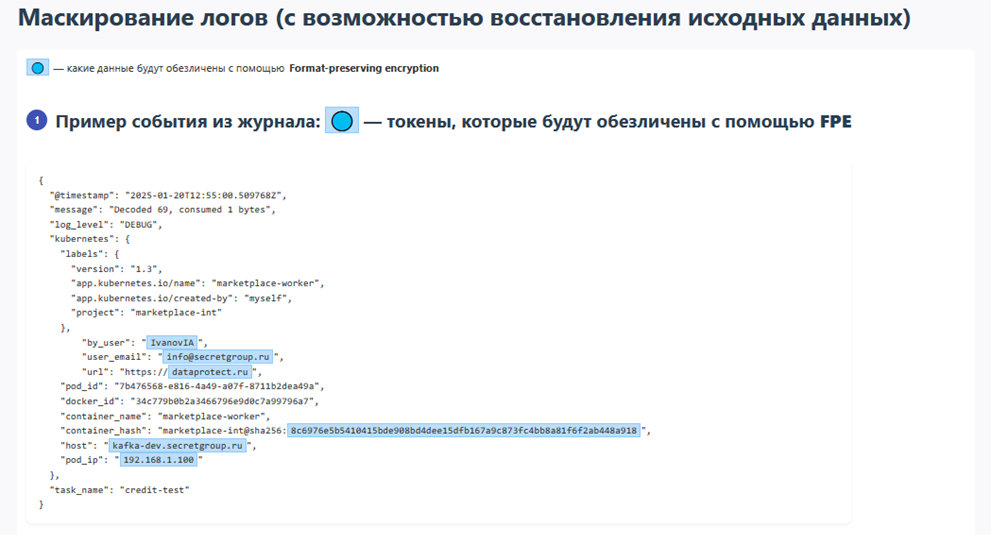
- Функционал маскирования логов с возможностью восстановления исходных данных;
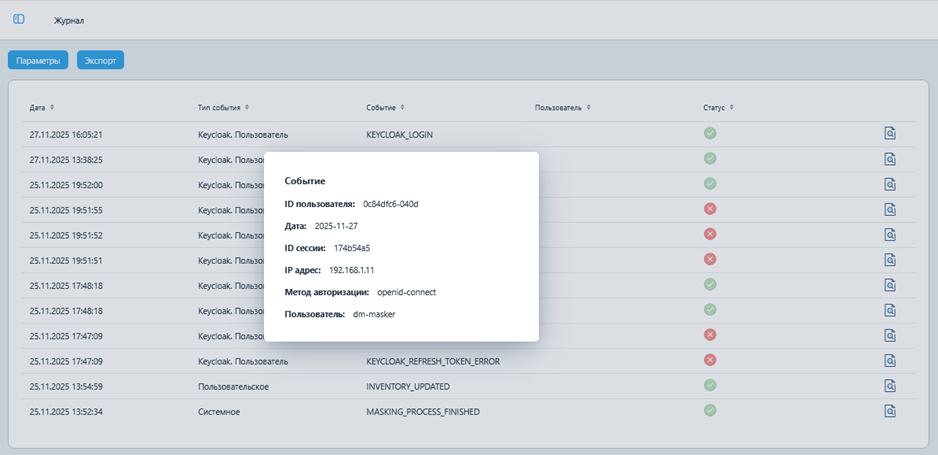
Журналирование — детальная фиксация всех авторизаций пользователей, запусков заданий маскирования и изменений конфигураций для обеспечения аудита и отслеживания процессов и изменений;
Эффективная система обезличивания данных должна быть комплексным решением, обеспечивающим баланс между технологической гибкостью и соответствием нормативным требованиям. При выборе продукта необходимо оценивать следующие ключевые аспекты:
1. Базовый функционал
- Автоматизированное профилирование данных с построением связей и структуры БД;
- Расширенный арсенал алгоритмов маскирования (токенизация, маскирование по словарю, посимвольная замена, маскирование дат, работа с бинарными данными);
- Поддержка режимов INSERT и UPDATE для СУБД;
- Детерминированность;
- Консистентность;
- Без внутреннего хранения замаскированных копий БД;
2. Нормативное соответствие
- Полное покрытие требований 152-ФЗ, Приказа №140 и Постановления №1154;
- Верификация результатов обезличивания;
- Детальный аудит и логирование всех операций;
3. Интеллектуальные возможности
- ML-алгоритмы для автоматического обнаружения конфиденциальных данных;
- Маскирование журналов транзакций и системных логов;
- Пользовательские сценарии обезличивания;
- Поиск конфиденциальной информации в бинарных данных;
4. Архитектурная гибкость
- Модульная архитектура с возможностью горизонтального масштабирования;
- API для интеграции с существующей ИТ-инфраструктурой;
- Конструктор пользовательских алгоритмов и генератор SQL скриптов обработки;
Система обезличивания данных — это не просто набор алгоритмов, а полноценная платформа, способная обеспечить безопасность, соответствие законодательству и высокую производительность. Специализированные решения выгодно отличаются от встроенных средств СУБД и самописных скриптов наличием готовых алгоритмов, адаптированных под российские требования, а также использованием «Machine learning» для поиска конфиденциальных данных. Они обеспечивают масштабируемость, детальный аудит и гибкую интеграцию в ИТ-ландшафт. В итоге такие системы позволяют организациям снижать риски, ускорять внедрение и гарантировать надежный уровень защиты.
Автор: Владышевский Иван Максимович, ведущий специалист по ИБ компании Secret Technologies.
