




Как развернуть отказоустойчивый кластер NGFW на российских решениях

Представьте ситуацию: в серверной вышел из строя ключевой коммутатор, или, что еще хуже, весь ЦОД оказался в зоне коммунальной аварии. CRM не работает, бухгалтерия не может отправить платежи, сайт не открывается. Более того, вместе с частью инфраструктуры вышли из строя защитные решения, и появился риск получить вдобавок к аварии еще и кибератаку. Чтобы этот страшный сон не стал реальностью, инженеры придумали «подстелить соломку» при помощи кластеризации.
Инженер сетевой безопасности Бастиона, Богдан Цой, расскажет о том, как превратить точку отказа в отказоустойчивую систему на примере российского NGFW-решения UserGate. Разберем не только техническую сторону (режимы Active/Passive, Active/Active, VRRP, синхронизацию сессий), но и практические моменты: как настраивать кластер, какие подводные камни ждут на каждом этапе.
Статья будет полезна системным администраторам, которые планируют внедрение отказоустойчивого периметра, и техническим руководителям, которым предстоит курировать этот непростой процесс.
Этап 0: Планирование — семь раз отмерь
Как показывает практика, 90% трудностей при внедрении кластера возникают из-за недостаточной подготовки. Разберем, что нужно сделать на нулевом этапе внедрения отказоустойчивой системы.
Формируем команду и техническое задание
Развертывание кластера — не сольный проект. Для реализации внедрения кластера понадобится слаженная команда из ряда технических специалистов:
- Инженер внедрения (от интегратора) — это главный проводник в мире NGFW;
- Сетевой инженер (со стороны заказчика) — человек, который знает корпоративную сеть как свои пять пальцев. Без него невозможна успешная интеграция;
- Системный администратор (со стороны заказчика) — курирует серверы, почту, Active Directory и другие сервисы, которые будут взаимодействовать с кластером.
- Специалист по ЦОД (опционально) — если есть выделенный сотрудник, отвечающий за оборудование в стойках, его участие обязательно.
Что касается грамотного ТЗ, то оно начинается с ответов на простые, но ключевые вопросы.
- Какие системы защищаем: ERP, CRM, биллинг?
- Насколько критичен их простой: счет идет на секунды, минуты или часы (от этого зависит, нужна ли синхронизация сессий)?
- Сколько пользователей генерируют трафик и какого он типа?
- Выполняется миграция с существующего решения, например, Cisco или Fortinet, или инсталляция «с чистого листа»?
Ответы позволят определить архитектуру, сложность политик безопасности и, в конечном счете, сроки работ. Такие проекты включают миграцию сотен политик, интеграцию со сложной сетевой топологией и отладку взаимодействия с десятками внутренних сервисов. Все это может занять несколько месяцев, даже если работы проходят четко по плану и без форс-мажоров.
Аудит инфраструктуры
Если система переносится на UserGate с другого устройства, то первый шаг — это аудит. Нужно досконально изучить текущую конфигурацию. Если это новая инсталляция, следует сосредоточиться на следующих моментах:
- IP-адресация — частый «камень преткновения» в подобных проектах. На каждый интерфейс кластера понадобится минимум три IP-адреса: по одному на физический интерфейс каждой ноды и один виртуальный (VIP). Нужно убедиться в наличии свободных адресов, иначе в середине проекта придется срочно перекраивать всю сетевую схему.
- Физическое размещение — хватит ли портов на коммутаторах? Есть ли место в стойке для двух или более устройств? Нельзя забывать про выделенный интерфейс для синхронизации (Sync Link) — его лучше подключать напрямую между нодами, минуя коммутаторы. Это не только быстрее, но и исключает коммутатор как единую точку отказа для самого кластера.
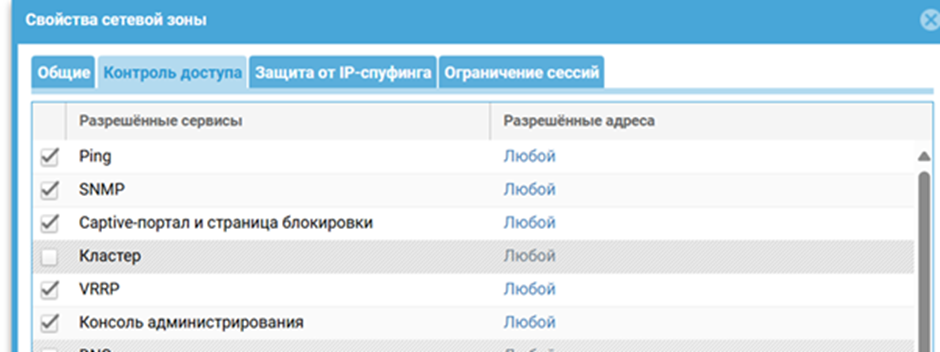
- Требования к зонам — для интерфейса, через который ноды будут обмениваться служебной информацией, нужно создать отдельную зону с разрешенным сервисом «Кластер». Это вопрос функциональности и безопасности.
В идеальной схеме WAN- и LAN-интерфейсы каждой ноды подключены к разным физическим коммутаторам, а Sync-линк (port4) соединен напрямую. Так достигается максимальная отказоустойчивость.
Обзор российских NGFW-решений: выбираем инструмент
На российском рынке есть три основных игрока, разрабатывающих решения для защиты периметра: UserGate, «Инфотекс» и «Код Безопасности». На первый взгляд они конкуренты, но на самом деле занимают разные ниши.
UserGate — классический NGFW (Next-Generation Firewall). Его преимущество в глубоком анализе трафика (L7), контроле приложений, IPS, веб-фильтрации и других функциях, которые позволяют строить гранулированные политики безопасности. По сути, это цифровой охранник на входе в вашу сеть, который проверяет не только IP-адрес, но и данные приложений.
«Инфотекс» (продукты ViPNet) и «Код Безопасности» («Континент») — в первую очередь криптошлюзы. Их основная задача — поддерживать защищенные VPN-туннели с использованием ГОСТ-шифрования. Это требование регуляторов для многих государственных и финансовых организаций. Можно сказать, что в их случае NGFW-функционал несколько вторичен.
| Параметр | UserGate | Инфотекс (ViPNet) / Код Безопасности (Континент) |
| Основной сценарий | Защита периметра, контроль приложений, веб-фильтрация (NGFW) | Построение защищенных сетей (VPN-шлюз) |
| VPN | Стандартный IPsec | ГОСТ, IPsec |
| Сильные стороны | Глубокий анализ трафика (L7), удобство управления политиками | Сертификация ФСБ, соответствие требованиям регуляторов по криптографии |
| Кластеризация | Гибкие режимы Active/Active и Active/Passive | Присутствует, но часто с фокусом на отказоустойчивость VPN-туннелей |
Что же выбрать? На практике часто используется гибридный подход. UserGate ставится на периметр для NGFW-фильтрации, а решения от «Инфотекс» или «Код Безопасности» — для организации ГОСТ VPN-туннелей с филиалами или партнерами.
Сегодня фокусируемся на UserGate, так как именно он предлагает более гибкую кластеризацию для задач NGFW.
Как устроен UserGate: погружение в архитектуру
UserGate реализует кластеризацию на двух уровнях. Важно понимать их различие.
Кластер Конфигурации — объединенные в нем устройства используют единые настройки: политики, правила, объекты. Изменили что-то на одном узле — настройки тут же реплицировались на все остальные. Это ядро, без которого кластеризация не заработает.
Кластер Отказоустойчивости — уже периферия. Он отвечает за то, чтобы в случае сбоя одного из узлов трафик мгновенно и бесшовно переключился на другой. Это достигается благодаря протоколу VRRP (Virtual Router Redundancy Protocol).
VRRP сравним с колл-центром: когда клиент звонит на общий номер, ему все равно, какой именно оператор ответит. В данном случае этот «общий номер» — виртуальный IP-адрес (VIP). Все пользователи и системы в сети отправляют трафик именно на него. За этим VIP-адресом скрываются два или более физических устройства. Одно из них — Master, который активно владеет этим IP и обрабатывает весь трафик. Второе — Backup, ждущий своего часа.
Master-узел постоянно рассылает в сеть специальные пакеты (VRRP Advertisement), сообщая всем компонентам, что он в строю и никаких сбоев нет. Если эти пакеты перестают приходить, Backup-узел понимает, что Master «упал», сам захватывает VIP и становится новым Master’ом.
Для конечного пользователя это переключение происходит практически незаметно. Его сессия не разрывается, потоковое видео не прерывается. Отказоустойчивость достигнута. При этом UserGate поддерживает два режима работы кластера отказоустойчивости.
Режим «Активный-Пассивный» (Active/Passive)
Это классическая и самая надежная схема. Один узел (Master) обрабатывает 100% трафика. Второй (Passive) простаивает, но находится в полной боевой готовности и постоянно синхронизирует состояние сессий с мастером.
Переключение происходит, если Master-нода перестает отвечать, прерывается интернет-канал или происходит сбой ПО.
- Плюсы: предсказуемость, надежность и простое диагностирование проблем.
- Минусы: бездействие второй ноды, ресурсы которой по большей части простаивают.
Режим «Активный-Активный» (Active/Active)
Схема для тех, кто хочет выжать максимум из своего «железа». В ней оба узла активны и обрабатывают трафик. Master-узел выполняет балансировку нагрузки, распределяя новые сессии между всеми нодами кластера поочередно — механизм Round-robin для ARP-ответов.
Если один из узлов вдруг выходит из строя, оставшийся в строю берет на себя всю нагрузку. Поэтому важно убедиться, что его производительности хватит, чтобы выдержать пиковый трафик в одиночку.
- Плюсы: Эффективное использование ресурсов обоих устройств.
- Минусы: Сложнее в настройке и диагностике. Не все функции UserGate, например, некоторые виды VPN или сложная маршрутизация, идеально работают в этом режиме. Нет «двойного прироста» трафика при одновременной работе двух нод из-за отсутствия в UserGate встроенного балансировщика. Особенно это критично, когда один узел выходит из строя, а второй вынужден обрабатывать весь трафик в одиночку и «держать в голове», что это кластер Active/Active. Чтобы отказоустойчивая система в таком режиме работала полноценно, требуется отдельное решение для балансировки нагрузки.
Построение кластера: пошаговое руководство
Итак, теория позади, переходим к практике. Вот упрощенная последовательность действий.
Этап 1. Сборка кластера конфигурации
Шаг 1: Подготовка кластерного интерфейса на первой ноде (будущем Master)
Что делаем: Заходим в веб-интерфейс первого устройства. Выбираем интерфейс для синхронизации — традиционно это port4. Назначаем ему статичный IP-адрес и помещаем в специальную зону, например, Cluster-Sync, в которой в разделе «Контроль доступа» включен сервис «Кластер».
Через этот интерфейс ноды будут обмениваться конфигурациями и служебной информацией. Изоляция этого трафика в отдельную зону — хорошая практика безопасности.
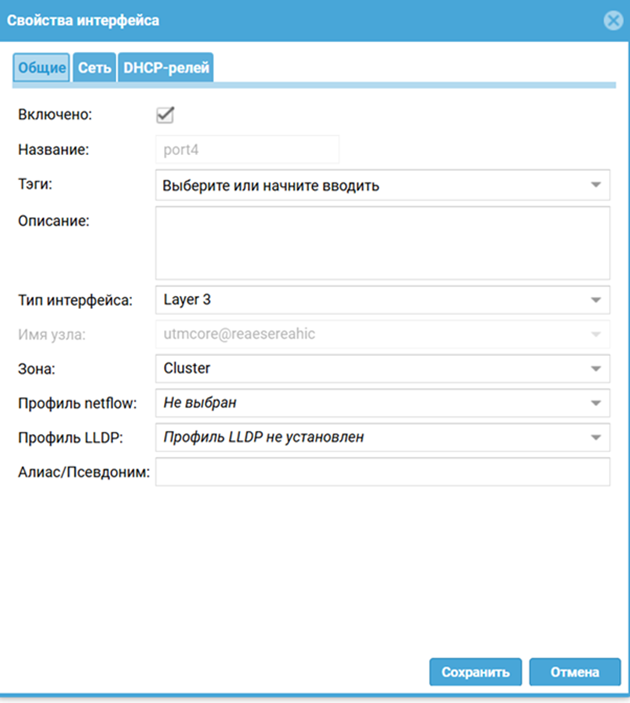
Шаг 2: Инициализация кластера на первой ноде
Что делаем: Переходим в раздел Кластеры → Кластер конфигурации. Нажимаем «Инициализировать». Система попросит перезагрузиться. После перезагрузки генерируем секретный код.
Таким образом мы превращаем одиночное устройство в «Мастер» кластера конфигурации. Секретный код — одноразовый ключ, с помощью которого другие ноды смогут к нему подключиться.

Шаг 3: Подключение второй ноды
Что делаем: Подключаемся к веб-интерфейсу второго устройства. Настраиваем на нем интерфейс управления. При первоначальной инициализации выбираем «Подключиться к кластеру». Указываем IP-адрес кластерного интерфейса Master-ноды и вводим сгенерированный ранее секретный код.
Вторая нода запрашивает у первой разрешение на подключение и, получив его, полностью скачивает всю конфигурацию и становится ведомой.
В итоге кластер конфигурации собран. Теперь оба устройства — единое целое с точки зрения настроек.
Этап 2. Сборка кластера отказоустойчивости (нервная система)
Шаг 1: Включение VRRP на «боевых» интерфейсах
Что делаем: На мастере (конфигурация синхронизируется) заходим в настройки сетевых интерфейсов, которые «смотрят» в локальную сеть (LAN) и во внешнюю (WAN). Для каждого из них в разделе «VRRP» ставим галочку «Включить VRRP».
Зачем: Даем команду этим интерфейсам «участвовать в выборах» Master-узла и быть готовыми подхватить виртуальный IP-адрес.
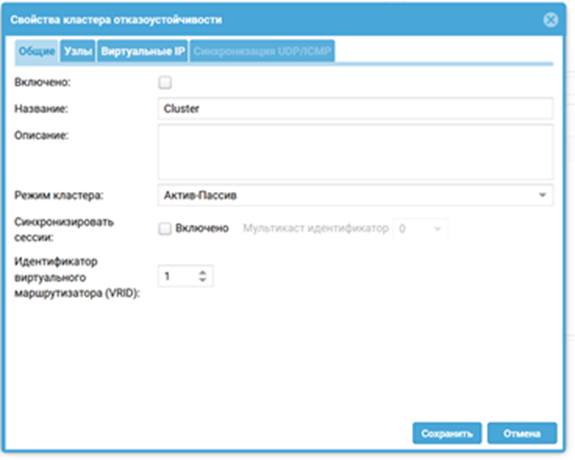
Шаг 2: Создание кластера отказоустойчивости
Что делаем: Переходим в Кластеры → Кластер отказоустойчивости. Создаем новый кластер, выбираем режим (например, Active/Passive) и даем ему имя.

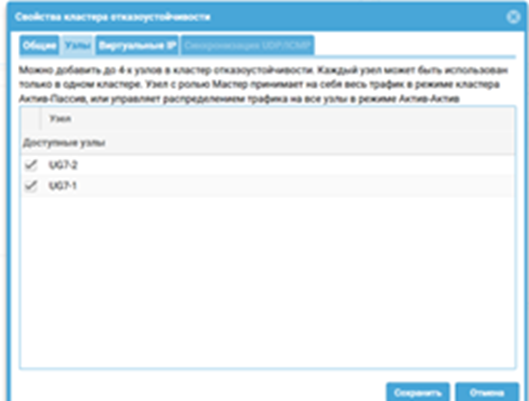
Шаг 3: Назначение нод и виртуальных IP-адресов
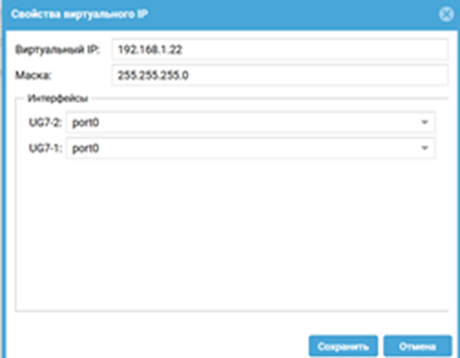
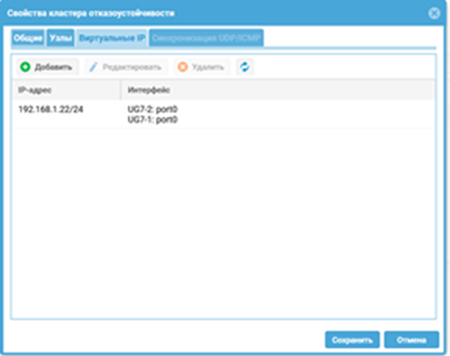
Что делаем: Добавляем в созданный кластер обе наши ноды из кластера конфигурации. Для каждой пары интерфейсов (например, port1 на обеих нодах, который смотрит в LAN) задаем общий виртуальный IP-адрес (VIP). Этот адрес и будет шлюзом по умолчанию для пользователей. То же самое повторяем для WAN-интерфейса.
Таким образом, определяем, какие физические интерфейсы будут бороться за какой виртуальный адрес. Именно этот VIP и обеспечивает «бесшовность» переключения. После сохранения настроек кластер начнет свою работу. Master-узел захватит VIP-адреса, и трафик потечет через него.
Действия после внедрения: мониторинг и тестирование
Собрать кластер — полдела. Важно убедиться, что он сработает в реальных аварийных ситуациях, а не только в лабораторных условиях.
Распространенная ошибка: Собрать кластер, увидеть, что все работает, и забыть про него. Необходимо регулярно тестировать сценарии отказов. Кластер, работающий полгода без проверок, — это большой риск.
Инструменты мониторинга
Встроенные средства UserGate: Дашборды и логи самого устройства — первый источник информации. Настройте оповещения по почте о важных событиях.
SNMP и Syslog: Интегрируйте кластер с централизованной системой мониторинга (Zabbix, Grafana и т.д.). Это стандарт де-факто для серьезного продакшена. Вендор предоставляет MIB-файлы для удобной настройки.
Линуксовые скрипты: Не игнорируйте сторонние инструменты, которые иногда рекомендует сам вендор и сообщество. Существуют готовые скрипты для мониторинга состояния кластера, которые можно легко развернуть на отдельной виртуальной машине.
Базовая проверка: классический failover
Самый наглядный тест — имитация сбоя. Запустите непрерывный пинг на какой-нибудь внешний ресурс (ping 8.8.8.8 -t) с компьютера в вашей сети. Затем просто выдерните питание из master-ноды.
Если все настроено правильно, вы увидите потерю одного-двух пакетов, после чего пинг восстановится. Это означает, что backup-узел подхватил роль и трафик пошел через него.
Связь между файрволами оборвалась
Самый критический дефект кластеров — ситуация, когда связь между нодами пропадает, и обе считают себя главными. В сети появляется два устройства с одинаковыми IP-адресами. В результате соединения рвутся, а коммутаторы не понимают, куда направлять трафик.
Чтобы проверить этот сценарий, подключите файрволы напрямую друг к другу отдельным кабелем, а не через коммутатор — это важно. Включите tie-breaker, приоритеты, link-monitor. Настройте приоритеты и правила, которые определяют, кто должен остаться главным при потере связи.
Теперь разорвите только sync-линк. WAN/LAN трогать не нужно. Параллельно пропускайте умеренный трафик через кластер, держите открытые TCP-сессии.
Наблюдайте за поведением. Главным должен остаться только один файрвол. У второго в логах должна появиться запись наподобие «потерял связь с напарником, остаюсь резервным». Верните sync и проследите, не возник ли MAC-flapping на коммутаторах.
Не выполняется автоматическое переключение между нодами
Оборудование узла может попросту сбоить, и тогда автоматическое переключение между нодами не происходит, когда это необходимо. Например, так бывает при большом износе и плачевном состоянии «железа» одной из нод. В таком случае выход один: все проверить и переключиться между узлами в ручном режиме.
Вместо заключения
Кластеризация — это как страховка от пожара. Оценить такие инвестиции по достоинству можно только при возникновении соответствующих рисков, которые удается успешно нейтрализовать.
Российские решения, такие как UserGate NGFW, прошли долгий путь и сегодня предлагают зрелый и функциональный инструментарий для обеспечения защиты и непрерывности бизнеса даже в условиях сбоев. Да, у них есть свои особенности, и они не всегда могут похвастаться проработанностью зарубежных аналогов, однако при грамотном планировании отечественные решения позволяют выстроить надежную и отказоустойчивую систему защиты.
И это уже не просто импортозамещение, а прагматичный выбор.
