

Обучение нейросети на логах и телеметрии для динамического анализа поведения приложений и обнаружения zero-day

Изображение: dall-e
В современном мире, где атаки и методы их реализации совершенствуются на ходу, ключевую роль в своевременном и точном обнаружении играет грамотно выстроенная стратегия обнаружения. Кроме того, особую опасность представляет тот факт, что часть злоумышленников прекрасно владеет техниками Prompt Engineering для запросов к AI-ассистентам (Artificial Intelligence), которые работают на базе LLM(Large Language Model)и NLP(Natural Language Processing).Вторая не менее опасная часть обладает высоким уровнем компетенций, способная находить и эксплуатировать zero-day.Эта тенденция создает серьезные и реальные угрозы безопасности не только отдельным организациям, но и всему обществу в целом.
Если говорить о поведении наблюдаемого объекта в контексте обнаружения zero-day, то наиболее корректным будет использовать подход на основе профилирования. В основе данного подхода находится банальный анализ величины отклонения наблюдаемого поведения от эталонного профиля нормального поведения. Сравнивая эту величину с заданным пределом, становится возможным обнаружить отклонения в поведении, что может свидетельствовать как о простой аномалии, так и о деструктивном воздействии.
Но тут появляются ряд вопросов.
- Какие данные анализировать?
- Чем анализировать?
- Как рассчитывать пороговое значение?
Если говорить о приложении, то справедливо будет заметить, что в настоящее время как правило, большинство приложениймикросервисные (разделенные на компоненты).Анализировать можно как поведение всего приложения, и так и его отдельных компонентов. Принцип будет один и тот же.
Теперь нужно понять какие данные анализировать. Тут все достаточно непросто, ведь опираться необходимо на специфику и данные конкретной операционной системы (ОС). Например,вся работа в ОСсемейства Linux завязана на использовании системных вызовов (systemcalls, syscalls). Рассмотрим простой инструмент мониторинга событий ОС—Auditd.Ядро Linux через подсистему аудита ядра (KernelAuditSubsystem) предоставляет в Auditd информацию о syscalls, которые выполняются процессами в системе(например, открытие файла, создание процесса, изменение атрибутов файла и т.д.). Если в правиле Auditdесть такое событие, то Auditd регистрирует его.
В ОС семейства Windowsситуация похожая,но с некоторыми отличиями.Когда происходит событие, драйвер аудита перехватывает его и передает в локальную службу безопасности(Local Security Authority,LSA). LSA, в свою очередь, создает запись в журнале безопасности, если политика аудита настроена на логирование данного события. Таким образом,в Windowsнемного другой подход. Аудит организован на более высоком уровне абстракциии фокусируетсяне на каждом syscalls, как это делается в Linux, а на типах событий.Кроме того, процесс перехвата syscallsв Windowsне самая простая задача. Также следует заметить, что если в логахAuditdсодержит все события, то в Windows события структурированы по различным категориямжурналов. ВWindowsсуществует несколько основных журналов событий:
— журнал безопасности. Регистрирует действия, которые могут быть связаны с нарушением политики безопасности; попытки несанкционированного доступа; изменения в правах доступа; вход и выход из системы; использование привилегий и т.д.
— журнал приложений. Регистрирует события, генерируемые приложениями. Это могут быть ошибки, предупреждения, информационные сообщения или события, специально заложенные разработчиками для диагностики.
— журнал системы. Регистрирует события, связанные с работой ОС и драйверов устройств, чтовключает в себя ошибки оборудования, проблемы при загрузке системы, сообщения от драйверов, сбои служб и т.д.
Теперь можно переходить к вопросу, чем анализировать.Все мы прекрасно знаем про такой «черный ящик», как нейронные сети. И это не удивительно, ведь мало кто представляет, как это работает. Нейронные сети или методы глубокого машинного обучения являются подмножеством области машинного обучения. В частном случае, машинное обучение можно рассматривать как серию математических алгоритмов. Но вернемся к нейронным сетям. Нейронные сети организованы по принципу и подобию человеческого мозга, но в своей основе содержат математические функции, с помощью которых становится возможным выполнять задачи, которые мы ассоциируем с когнитивными функциями. Почему же все-таки нейронные сети, а не методы машинного обучения? На самом деле, ответ достаточно простой. Они точнее и быстрее за счет использования только числовых признаков и нелинейных функций активации.
Рассмотрим гибридную нейронную сеть AE-LSTM (Autoencoder и Long short-termmemory) для анализа поведения приложений и обнаружения аномалий.
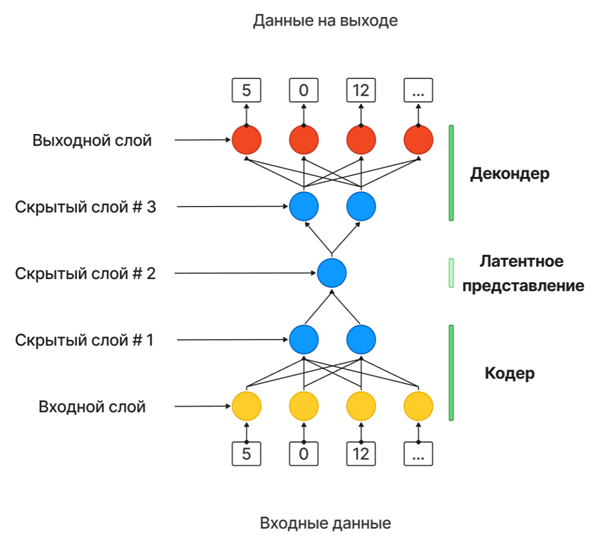
В основе модели лежат два симметричных компонента: кодировщик (Encoder) и декодировщик (Decoder). Encoder преобразует входные данные в компактное представление меньшей размерности (Latensspace), а Decoder восстанавливает данные из Latensspace в исходный вид. В процессе обучения модель стремится максимально точно восстанавливать входные данные, минимизируя ошибку реконструкции.Данная модель усилена слоями LSTM, что значительно повышает точность обнаружения аномалий по двум причинам. Во-первых, классическая модельAE показала бы значительно более низкую точность на данных о поведении.Во-вторых, данные о поведении имеют последовательную природу, и LSTM, в отличие от обычной RNN (Recurrentneuralnetwork), обеспечивает более точное моделирование хронологических последовательностей и долгосрочных зависимостей, позволяя учитывать взаимосвязь между данными на текущем и предыдущих шагах.
Во время обнаружения аномалий выполняется анализ величины ошибки реконструкции: если ошибка существенно превышает ожидаемую, это свидетельствует о том, что модель не смогла корректно восстановить данные.Таким образом, большая ошибка реконструкции указывает на то, что модель не была обучена восстанавливать эти конкретные данные, что позволяет идентифицировать их как аномальные.
Теперь перейдем к пороговому значению, для определения которого существует множество подходов и не существует универсального решения. Выбор оптимального метода зависит от конкретной задачи: например, в одних случаях подойдет порог, основанный на уровне потерь в процессе обучения модели, а в других — сумма среднеквадратичной ошибки (MeanSquaredError, MSE) и ее стандартного отклонения.
Теперь перейдем к подготовке данных для обучения. В качестве примера рассмотрим анализ событий syscalls. После сбора последовательностиsyscall необходимо выполнить ее предобработку, чтобы подготовить данные к обучению. Прежде всего, требуется создать последовательности фиксированной длины, для чего удобно использовать метод скользящего окна с единичным смещением. Затем эти последовательности необходимо преобразовать в числовые признаки. Для этого понадобится унифицированный список всех syscalls, в котором каждому syscall будет присвоен уникальный числовой идентификатор.Полученные последовательности представлены листинге 1.
Листинг 1. Преобразованные последовательности syscalls

После можно переходить к созданию модели нейронной сети. Размер входного и выходного слоев будет соответствовать длине последовательности. Первый и третий скрытые слои будут содержать вдвое меньше нейронов,а второй скрытый слой в четверо. Такая архитектура позволяет предотвращать переобучение модели, сосредотачиваясь на наиболее значимых признаках.
Для обучения будем использовать комбинацию алгоритма оптимизации ADAM (Adaptive Moment Estimation) и функции потерь MSE (Mean Squared Error), что позволит автоматически подстраивать параметры модели и скорость обучения для каждого из этих параметров. Процесс обучения представлен в листинге 2.
Листинг 2. Процесс обучения модели нейронной сети AE-LSTM
Кроме того, следует сказать про параметры обучения, такие как эпохи обучения (epoch) и размер пакета (batchsize).Epochуказывает, сколько полных проходов будет совершено по всему обучающему набору данных, а batch указывает, сколько примеров данных обрабатывается моделью за одну итерацию обновления весов. Настройка этих параметров так же, как и выбор порогового значения, не имеет однозначного ответа, но цель у них общая — повышение уровня точности модели.
Для обнаружения будем использовать расчет порога ошибки реконструкции на основесуммыMSE и ее стандартного отклонения. Процесс обнаружения представлен в листинге 3.
Листинг 3. Процесс обнаружения

В заключении важно отметить, что чем сложнее архитектура модели нейронной сети, тем дольше будет процесс обучения. Кроме того,на скорость обучения также влияют параметры epoch и batchsize.
Автор: Максим Мельник, инженер-аналитик аналитического центра кибербезопасности компании «Газинформсервис»
