




Регулярная переаттестация серверов в эксплуатации: контроль конфигурации, оценка устаревших компонентов и план замены

Введение
В современных информационных системах эксплуатация серверов представляет собой не только поддержание их работоспособности, но и постоянный контроль их соответствия требованиям безопасности. Одной из ключевых практик становится регулярная переаттестация. В неё входят процессы, включающие аудит конфигураций и тестирование на проникновение, анализ используемых компонентов (инвентаризация) и планирование их безопасной сборки и миграции данных.
В данном материале будут проанализированы различные подходы к обеспечению безопасности за счёт переаттестации серверов, приведены примеры уязвимостей компонентов новых версий, повлекших компрометации систем, и рассмотрены различные подходы плановой замены компонентов сервисов информационных систем.
Регулярная переаттестация серверов в эксплуатации
Использование устаревших компонентов эксплуатируемого сервиса может привести к раскрытию конфиденциальной информации или даже компрометации системы. Это связано с тем, что большинство таких сервисов являются open source, особенно в случае эксплуатации Linux-based систем. Открытый исходный код может быть изучен и улучшен энтузиастами, что и подразумевает модель open source. Однако не все умельцы, изучающие безопасность сервисов, желают действовать во благо. Некоторые из них подробно изучают код на предмет изъянов, приводящих к уязвимостям для своих корыстных целей.
Важно отметить, что обстановка с системами, не раскрывающими исходный код (к примеру, сервисами на базе Windows), наблюдается такая же, что и с открытыми системами, а также то, что их изучение представляет собой метод чёрного ящика и, как следствие, не уменьшает количество проблем. Критические уязвимости часто публикуются в исследовательских работах о подобных системах.
Нередко бывают случаи, когда новые версии используемого ПО вендора вызывают новый пласт серьёзных уязвимостей, что требует срочных действий от инженеров безопасности. Новые патчи систем вызывают новые вектора атак из-за ошибок разработчиков продукта новой версии.
Так, в начале 2026 года было опубликовано исследование довольно популярной уязвимости CVE-2026-24061, вызвавшей некоторое волнение в сообществе специалистов по безопасности.
Данная уязвимость получила 9,8 балла по шкале CVSS:3.1 (оценка организации MITRE). Она затрагивает GNU InetUtils версий от 1.9.3 (релиз 2015 г.) до 2.7 включительно (релиз декабря 2025 г.). Проблему исправили только в версии 2.8, которая вышла в январе 2026 года. Примечательно, что проблема оставалась незамеченной почти 11 лет.
Баг позволяет удаленному злоумышленнику получить root-доступ к целевой системе, полностью минуя аутентификацию и не требуя знания пароля того же root пользователя.
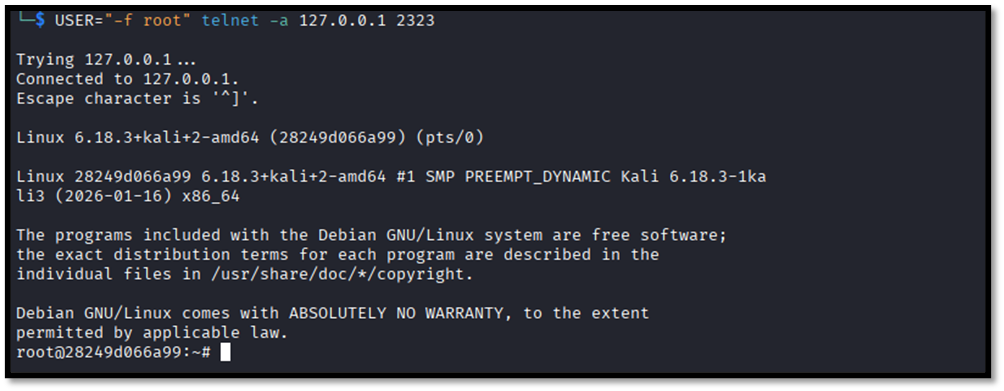
Сервер передаёт программе /usr/bin/login значение переменной USER, полученное от клиента, без дополнительной проверки. Злоумышленник может указать значение USER как -f root. Для /usr/bin/login данный параметр интерпретируется как указание, что пользователь уже прошёл аутентификацию. При подключении через telnet с флагами -a или –login, позволяющими передать имя пользователя без интерактивного ввода, /usr/bin/login воспринимает -f root как служебный флаг, пропускает стандартную процедуру проверки подлинности и автоматически предоставляет права пользователя root.
Благо, в случае с этой уязвимостью патч вышел в тот же день, когда были раскрыты детали уязвимости. В версии компонента GNU InetUtils 2.8 данная уязвимость уже не валидна.
До публикации исследования данной уязвимости в предыдущих версиях инженерам по безопасности приходилось откатывать инструмент к более безопасным версиям ранее или полностью же закрывать доступы к портам. Для сложного решения также нужно было исключить из возможных для использования функций telnet-сервис, приводящих к вредоносным действиям. В противном случае крупные компании рисковали потерять свои активы. При выходе новой безопасной версии вендора достаточно было лишь обновить компонент.
Каких-либо громких компрометаций при помощи данной уязвимости в сети пока что отмечено не было, однако сразу после публикации информации о ней команда исследователей GreyNoise построила honeypot-систему, чтобы отследить реальные попытки эксплуатации. Атакующие не заставили себя ждать, и за 18 часов наблюдений было зафиксировано 60 попыток взлома с 18 уникальных IP-адресов. (Подробнее в исследовании)
Исследователи отмечают, что эта уязвимость позволила специалистам по безопасности собрать ценные данные об актуальных тактиках и инструментах злоумышленников.
Уязвимости также встречаются в новых версиях ядра и внутренних компонентов систем, требующих проникновения в систему ранее по цепочке атаки.
Уязвимость CVE-2025-32463 в sudo, известная как Chwoot, позволяет любому локальному пользователю системы получить полные права root. Это связано с тем, что в определённых версиях программы сбой произошёл в порядке выполнения операций: команда sudo сначала переключалась в указанную пользователем изолированную среду (chroot) и только после этого пыталась проверить, есть ли у этого пользователя права на выполнение запроса. Злоумышленник может создать поддельное окружение с особым конфигурационным файлом, который заставит sudo загрузить вредоносную библиотеку из этого окружения. Поскольку переключение среды происходит до проверки прав, вся последующая работа, включая загрузку библиотеки, выполняется уже с привилегиями root, что даёт атакующему полный контроль над системой.
Уязвимость затрагивает версии sudo с версии 1.9.14, которая вышла в июне 2023 года, до версии 1.9.17, выпущенной в июне 2025 года. Именно в этом промежутке версий в коде присутствует ошибка, позволяющая выполнить атаку.
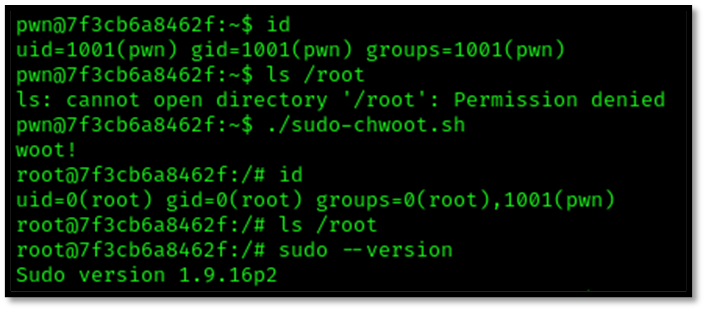
Агентство по кибербезопасности США (CISA) официально добавило CVE-2025-32463 в свой каталог эксплуатируемых уязвимостей (Known Exploited Vulnerabilities, KEV) – доказательство того, что в природе существуют атаки, использующие этот баг.
CISA внесла эту уязвимость в список из-за высокой вероятности её использования злоумышленниками и, как следствие, реальной угрозы для государственных и частных организаций, а значит, уязвимость уже оставила отпечатки в не раскрываемых цепочках атак на организации.
Вышеприведённые примеры подтверждают, что системы, поддерживающие актуальные версии программных компонентов, могут также быть подвержены атакам из-за изъянов в их коде, повлекших за собой опасные последствия. Это заставляет специалистов отслеживать информацию о найденных проблемах в различных используемых версиях ПО до того, как это станет критической проблемой.
Тем не менее, недостаточно просто своевременно устанавливать обновления. Как показывает практика, опасные уязвимости могут существовать в коде годами, оставаясь незамеченными, и выявляться уже после того, как решение станет стабильной версией. Пример с CVE-2026-24061 в GNU InetUtils демонстрирует, что ошибка, внесённая в 2015 году, ждала своего часа 11 лет и что даже полностью обновлённая на тот момент система, где стояла последняя протестированная версия (например, 2.7), на деле была критически уязвима с первого дня своего развёртывания.
План замены при оценке/контроле конфигурации компонентов
Повсеместный контроль конфигураций и постоянный мониторинг уязвимостей создают каркас безопасности, но главная проблема в том, что они статичны. Такие подходы проверяют соответствие системы заранее заданным требованиям безопасности: сравнивают текущие параметры (версии ПО, открытые порты, права доступа, наличие известных CVE) с эталонными значениями, которые считаются безопасными. Это сравнение двух наборов дискретных данных — ожидаемого и фактического.
Регулярный пентест является не просто рекомендацией, а критически важной практикой, позволяющей контролировать безопасность серверной инфраструктуры при переаттестации. Контроль конфигураций может подтвердить, что межсетевой экран настроен по всем правилам, антивирус установлен и обновлен, а политики паролей соблюдаются. Тестирование на проникновение может показать, можно ли эти настройки обойти, если атаковать систему не по инструкции, а творчески, как это делает реальный злоумышленник. Часто оказывается, что формально правильная конфигурация содержит логическую ошибку или не учитывает нештатные сценарии использования.
После проведения переаттестации и оценки технического состояния инфраструктуры возникает необходимость определения дальнейшего жизненного цикла серверов и компонентов. На этом этапе принимается решение о модернизации, выводе из эксплуатации или полной замене инфраструктурных узлов. К примеру, в рамках DevSecOps-подхода процесс замены серверов рассматривается как часть непрерывного управления инфраструктурой, где ключевую роль играют автоматизация, безопасность, воспроизводимость конфигураций и минимизация эксплуатационных рисков. В зависимости от архитектурных особенностей среды и требований к доступности сервисов применяются различные методы замены серверной инфраструктуры.
В практике того же DevSecOps выделяют следующие популярные подходы:
- In-place replacement
- Rebuild-and-replace
- Rolling replacement
- Blue-green replacement
- Canary replacement
- Risk-based replacement
- Hybrid replacement strategy
Далее подробнее о каждом из приведённых способов.
Самым старым и до сих пор встречающимся подходом является in-place replacement. В этом случае существующий сервер актуализируют или постепенно заменяют его компоненты: обновляют ОС, firmware, диски, иногда переносят сервисы вручную. Такой подход считается наименее предпочтительным, потому что со временем сервер накапливает configuration drift (т.е. система со временем перестаёт соответствовать тому виду, в котором она должна находиться по документации), ручные изменения и трудно воспроизводимые состояния. Его используют там, где есть устаревшие системы или привязка к оборудованию.
Более современный подход — rebuild-and-replace. Серверу не меняют конфигурацию — его полностью пересоздают из эталонного образа. Новый экземпляр поднимается автоматически через IaC и CI/CD pipeline, проходит security-проверки, после чего нагрузка переключается на него, а старый сервер удаляется. Это уже классический DevSecOps-подход, потому что он обеспечивает воспроизводимость и минимизирует накопление скрытых изменений.
Также существует и подход rolling replacement — постепенная, поэтапная замена. В кластере или группе серверов ноды обновляются по одной или небольшими партиями, чтобы сервис продолжал работать без downtime. Это типично для Kubernetes, VMware clusters, load-balanced web tiers. Такой подход хорошо подходит для high-availability инфраструктуры.
Похожий, но более контролируемый вариант — blue-green replacement, предполагающий создание полностью новой инфраструктурной среды («green») рядом со старой («blue»). После тестирования трафик переключается на новую среду практически мгновенно. Если возникает проблема, можно быстро откатиться обратно. Этот подход часто используют для критичных production-систем, где риск downtime особенно чувствителен.
Canary replacement — ещё более осторожная стратегия. Новая инфраструктура получает сначала маленькую часть нагрузки или ограниченный набор сервисов. Если всё работает стабильно, замена продолжается.
Risk-based replacement — это подход, при котором серверы заменяются не по сроку службы и не по заранее заданному графику, а исходя из текущего уровня риска их эксплуатации. Основное внимание уделяется тому, насколько конкретный узел безопасен, соответствует требованиям регуляторов и способен стабильно выполнять свои функции в существующей инфраструктуре. В этом подходе сервер рассматривается через призму его актуального состояния: наличие уязвимостей, поддержка со стороны вендора, соответствие политиками безопасности и влияние возможного отказа на бизнес. Если совокупный риск становится выше допустимого уровня, система или инженеры принимают решение о замене, даже если оборудование формально ещё не устарело.
При выборе метода замены сервисных компонентов нет универсальных решений. Разные подходы могут быть одинаково применимы, но их эффективность зависит от уровня зрелости процессов, степени автоматизации инфраструктуры, требований к безопасности и критичности обслуживаемых систем.
В компаниях с высокой зрелостью в вопросах безопасной разработки и администрирования систем обычно используются более автоматизированные и предсказуемые модели, такие как rolling replacement, тогда как в менее зрелых средах могут сохраняться подходы, связанные с ручным обновлением. В высокорегулируемых или критичных инфраструктурах чаще применяются риск-ориентированные и гибридные стратегии, позволяющие учитывать не только техническое состояние систем, но и бизнес-риски. Выбор конкретного метода замены является задачей архитектурного и эксплуатационного уровня и определяется внутренними требованиями организации, её процессной зрелостью и допустимым уровнем риска, а не единственно правильной универсальной моделью.
Заключение
Таким образом, обеспечение безопасности серверной инфраструктуры при её эксплуатации и переаттестации представляет собой непрерывный и многослойный процесс, который не ограничивается установкой обновлений или формальным контролем конфигураций. Современные угрозы демонстрируют, что как устаревшие, так и актуальные версии программных компонентов могут содержать критические уязвимости, остающиеся незамеченными годами или появляющиеся непосредственно после выхода новых релизов. Это делает невозможным построение эффективной защиты исключительно на доверии к последней стабильной версии программного обеспечения.
Пентест в данном случае выступает как практический инструмент проверки реальной устойчивости инфраструктуры, позволяющий выявлять ошибки проектирования и логические недостатки, которые невозможно обнаружить только средствами автоматизированного аудита. Именно сочетание технического контроля, мониторинга угроз и практической проверки безопасности позволяет своевременно обнаруживать критические проблемы до их эксплуатации злоумышленниками.
Дополнительно важным этапом жизненного цикла инфраструктуры становится планирование замены серверов и компонентов. Современные подходы, применяемые в DevSecOps, смещают акцент с поддержки отдельных серверов на управление всей инфраструктурой.
Регулярная переаттестация серверов должна рассматриваться не как формальная процедура соответствия требованиям безопасности, а как непрерывный процесс анализа, контроля и адаптации инфраструктуры к изменяющимся угрозам. Только комплексное сочетание мониторинга, управления конфигурациями, своевременного реагирования на уязвимости, тестирования на проникновение и безопасных стратегий замены компонентов позволяет поддерживать устойчивость современных информационных систем к актуальным киберугрозам.

Автор: Александр Ястремской, специалист по тестированию на проникновение компании Compliance Control

